(换肤)
语言:

文章编号:11818时间:2024-10-01人气:
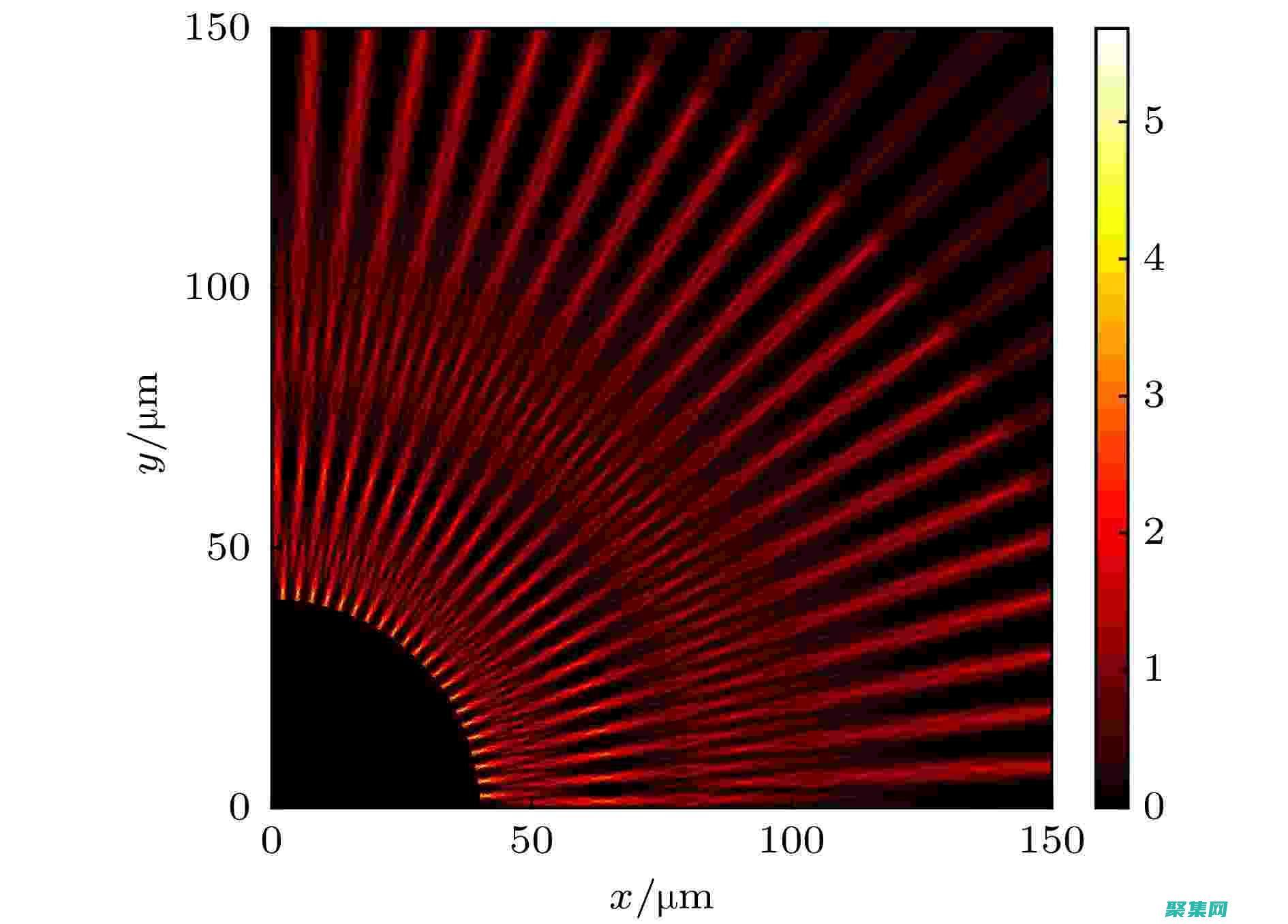
光栅化技术是数字显示领域的一项关键技术,它将矢量图形或文本转换为像素网格,以便在显示屏上显示。在这个过程中,每个像素都指定了图像或文本中某个点的颜色值,共同形成了一个离散的、点阵化的图像。
光栅化过程涉及以下步骤:
光栅化技术有多种,每种技术都有其优点和缺点:
光栅化技术有许多优点,包括:

光栅化技术也有一些缺点:
计算机在屏幕光栅化线段时,需在两端点间选择合理的像素进行点亮,以模拟线的连续性。 在屏幕像素组成的二维空间中,线段的光栅化是图形学中常见问题。 不同端点位置的线段,其光栅化结果可能大相径庭。 计算机需在两端点间合理选择像素,形成连续的线段。 为解决这一问题,图形学中常用到中点算法与Bresenham算法。 中点算法基于直线方程,其核心在于确定在每一步迭代中,下一个“点亮”的像素是其右侧还是右上方的像素。 算法通过计算像素中心点到直线的距离,决定下一步的移动方向。 当像素位于直线的上侧时,选择右上方像素;下侧时选择右侧像素。 通过这种方式,算法确保了线段的连续性,从而实现了线段的光栅化。 中点算法的关键在于直线方程的斜率。 当斜率大于或等于1时,Bresenham算法进行调整。 算法通过预计算增量,简化了每一步的决策过程,提高了效率。 这种方法避免了每次迭代都需要计算直线方程的值,减少了计算开销。 中点算法的改进版本是Bresenham算法,它采用增量思想,通过预计算增量值,简化了迭代过程中的计算步骤,提高了算法效率。 在三角形光栅化中,Bresenham算法的增量思想同样适用,通过计算重心坐标增量,提高了光栅化的效率,减少了计算量。 综上所述,计算机在绘制线段时,通过中点算法与Bresenham算法等方法,实现了在屏幕像素组成的二维空间中合理选择像素,形成连续线段的目标。 这些算法有效地解决了图形学中的线段光栅化问题,提高了计算机绘制图形的效率与质量。
目录:第一章:第二代及以后的GPU工作流程简介第二章:DirectX8和DirectX9 GPU的传统流水线第三章:顶点和像素操作指令第四章:传统GPU指令的执行第五章:统一渲染架构第六章:G80和R600的统一渲染架构实现第七章:G80与R600效能对比第八章:尴尬的中端--Geforce8600简析前面4章 我将先简要介绍下DirectX8/9显卡的核心----图形处理单元GPU的工作流程和指令处理情况从第5章开始讨论统一渲染架构、新一代DirectX10 GPU的特性,G80/Geforce8800与R600/RadeonHD2900XT的架构具体实现及其区别。 最后将会对中端最受关注的Geforce8600进行相应的简单分析。 第一章:第二代及以后的GPU工作流程简介简单(而不一定绝对科学)的说:GPU主要完成对3D图形的处理--图形的生成渲染。 GPU的图形(处理)流水线完成如下的工作:(并不一定是按照如下顺序)顶点处理:这阶段GPU读取描述3D图形外观的顶点数据并根据顶点数据确定3D图形的形状及位置关系,建立起3D图形的骨架。 在支持DX8和DX9规格的GPU中,这些工作由硬件实现的Vertex Shader(定点着色器)完成。 光栅化计算:显示器实际显示的图像是由像素组成的,我们需要将上面生成的图形上的点和线通过一定的算法转换到相应的像素点。 把一个矢量图形转换为一系列像素点的过程就称为光栅化。 例如,一条数学表示的斜线段,最终被转化成阶梯状的连续像素点。 纹理帖图:顶点单元生成的多边形只构成了3D物体的轮廓,而纹理映射(texture mapping)工作完成对多变形表面的帖图,通俗的说,就是将多边形的表面贴上相应的图片,从而生成“真实”的图形。 TMU(Texture mapping unit)即是用来完成此项工作。 像素处理:这阶段(在对每个像素进行光栅化处理期间)GPU完成对像素的计算和处理,从而确定每个像素的最终属性。 在支持DX8和DX9规格的GPU中,这些工作由硬件实现的Pixel Shader(像素着色器)完成。 最终输出:由ROP(光栅化引擎)最终完成像素的输出,1帧渲染完毕后,被送到显存帧缓冲区。 总结:GPU的工作通俗的来说就是完成3D图形的生成,将图形映射到相应的像素点上,对每个像素进行计算确定最终颜色并完成输出。 第二章:DirectX8和DirectX9 GPU的传统流水线前面的工作流程其实已经说明了问题。 本章来总结一下,承前启后。 传统的GPU功能部件我们不妨将其分为顶点单元和像素流水线两部分。 顶点单元由数个硬件实现的Vertex Shader组成。 传统的像素流水线由几组PSU(Pixel Shader Unit)+TMU+ROP组成。 于是,传统的GPU由顶点单元生成多边形,并由像素流水线负责像素渲染和输出。 对于像素流水线需要做的说明是:虽然传统的流水线被认为=1PSU+1TMU+1ROP,但这个比例不是恒定的,例如在RadeonX1000(不包括X1800)系列中被广为称道的3:1黄金架构,PSU:TMU:ROP的数量为3:1:1。 一块典型的X1900显卡具有48个PSU,16个TMU和16个ROP。 之所以采用这种设计方法,主要考虑到在当今的游戏中,像素指令数要远远大于纹理指令的数量。 ATI凭借这个优秀的架构,成功击败了Geforce7,在DX9后期取得了3D效能上的领先。 总结:传统的GPU由顶点单元生成多边形,像素流水线渲染像素并输出,一条像素流水线包含PSU,TMU,和ROP(有的资料中不包含ROP),比例通常为1:1:1,但不固定。 第三章:顶点和像素操作指令GPU通过执行相应的指令来完成对顶点和像素的操作。 熟悉OpenGL或Direct3D编程的人应该知道,像素通常使用RGB三原色和alpha值共4个通道(属性)来描述。 而对于顶点,也通常使用XYZ和W 4个通道(属性)来描述。 因而,通常执行一条顶点和像素指令需要完成4次计算,我们这里成这种指令为4D矢量指令(4维)。 当然,并不是所有的指令都是4D指令,在实际处理中,还会出现大量的1D标量指令以及2D,3D指令。 总结:由于定点和像素通常用4元组表示属性,因而顶点和像素操作通常是4D矢量操作,但也存在标量操作。 第四章:传统GPU指令的执行传统的GPU基于SIMD的架构。 SIMD即Single Instruction Multiple Data,单指令多数据。 其实这很好理解,传统的VS和PS中的ALU(算术逻辑单元,通常每个VS或PS中都会有一个ALU,但这不是一定的,例如G70和R5XX有两个)都能够在一个周期内(即同时)完成对矢量4个通道的运算。 比如执行一条4D指令,PS或VS中的ALU对指令对应定点和像素的4个属性数据都进行了相应的计算。 这便是SIMD的由来。 这种ALU我们暂且称它为4D ALU。 需要注意的是,4D SIMD架构虽然很适合处理4D指令,但遇到1D指令的时候效率便会降为原来的1/4。 此时ALU 3/4的资源都被闲置。 为了提高PS VS执行1D 2D 3D指令时的资源利用率,DirectX9时代的GPU通常采用1D+3D或2D+2D ALU。 这便是Co-issue技术。 这种ALU对4D指令的计算时仍然效能与传统的ALU相同,但当遇到1D 2D 3D指令时效率则会高不少,例如如下指令:ADD , R0,R1//此指令是将R0,R1矢量的x,y,z值相加 结果赋值给R0ADD R3.x , R2,R3//此指令是将R2 R3矢量的w值相加 结果赋值给R3对于传统的4D ALU,显然需要两个周期才能完成,第一个周期ALU利用率75% ,第二个周期利用率25%。 而对于1D+3D的ALU,这两条指令可以融合为一条4D指令,因而只需要一个周期便可以完成,ALU利用率100%。 但当然,即使采用co-issue,ALU利用率也不可能总达到100%,这涉及到指令并行的相关性等问题,而且,更直观的,上述两条指令显然不能被2D+2D ALU一周期完成,而且同样,两条2D指令也不能被1D+3D ALU一周期完成。 传统GPU在对非4D指令的处理显然不是很灵活。 总结:传统的GPU中定点和像素处理分别由VS和PS来完成,每个VS PS单元中通常有一个4D ALU,可以在一个周期完成4D矢量操作,但这种ALU对1D 2D 3D操作效率低下,为了弥补,DX9显卡中ALU常被设置为1D+3D 2D+2D等形式。 第五章:统一渲染架构相对于DirectX 9来说,最新的DirectX 10最大的改进在于提出了统一渲染架构,即Unified Shader。 传统的显卡GPU一直采用分离式架构,顶点处理和像素处理分别由Vertex Shader和Pixel Shader来完成,于是,当GPU核心设计完成时,PS和VS的数量便确定下来了。 但是不同的游戏对于两者处理量需求是不同的,这种固定比例的PS VS设计显然不够灵活,为了解决这个问题,DirectX10规范中提出了了统一渲染架构。 不论是顶点数据还是像素数据,他们在计算上都有很多共同点,例如通常情况下,他们都是4D矢量,而且在ALU中的计算都是没有分别的浮点运算。 这些为统一渲染的实现提供了可能。 在统一渲染架构中,PS单元和VS单元都被通用的US单元所取代,nVidia的实现中称其为streaming processer,即流处理器,这种US单元既可以处理顶点数据,又可以处理像素数据,因而GPU可以根据实际处理需求进行灵活的分配,这样便有效避免了传统分离式架构中VS和PS工作量不均的情况。 总结:统一渲染架构使用US(通常为SP)单元取代了传统的固定数目的VS和PS单元,US既可以完成顶点操作,又可以完成像素操作,因而可以根据游戏需要灵活分配,从而提高了资源利用率。 第六章:G80和R600的统一渲染架构实现以下我们着重讨论G80和R600的统一着色单元而不考虑纹理单元,ROP等因素。 G80 GPU中安排了16组共128个统一标量着色器,被叫做stream processors,后面我们将其简称为SP。 每个SP都包含有一个全功能的1D ALU。 该ALU可以在一周期内完成乘加操作(MADD)。 也许有人已经注意到了,在前面传统GPU中VS和PS的ALU都是4D的,但在这里,每个SP中的ALU都是1D标量ALU。 没错,这就是很多资料中提及的MIMD(多指令多数据)架构,G80走的是彻底的标量化路线,将ALU拆分为了最基本的1D 标量ALU,并实现了128个1D标量SP,于是,传统GPU中一个周期完成的4D矢量操作,在这种标量SP中需4个周期才能完成,或者说,1个4D操作需要4个SP并行处理完成。 这种实现的最大好处是灵活,不论是1D,2D,3D,4D指令,G80得便宜其全部将其拆成1D指令来处理。 指令其实与矢量运算拆分一样。 例如一个4D矢量指令 ADD , R0,R1R0与R1矢量相加,结果赋R0G80的编译器会将其拆分为4个1D标量运算指令并将其分派给4个SP:ADD R0.x , R0,R1 ADD R0.y , R0,R1 ADD R0.z , R0,R1ADD R0.w, R0,R1综上:G80的架构可以用128X1D来描述。 R600的实现方式则与G80有很大的不同,它仍然采用SIMD架构。 在R600的核心里,共设计了4组共64个流处理器,但每个处理器中拥有1个5D ALU,其实更加准确地说,应该是5个1D ALU。 因为每个流处理器中的ALU可以任意以1+1+1+1+1或1+4或2+3等方式搭配(以往的GPU往往只能是1D+3D或2D+2D)。 ATI将这些ALU称作streaming processing unit,因而,ATI宣称R600拥有320个SPU。 我们考虑R600的每个流处理器,它每个周期只能执行一条指令,但是流处理器中却拥有5个1D ALU。 ATI为了提高ALU利用率,采用了VLIW体系(Very Large Instruction Word)设计。 将多个短指令合并成为一组长的指令交给流处理器去执行。 例如,R600可以5条1D指令合并为一组5DVLIW指令。 对于下述指令:ADD , R0,R1//3DADD R4.x , R4,R5//1DADD R2.x , R2,R3//1DR600也可以将其集成为一条VLIW指令在一个周期完成。 综上:R600的架构可以用64X5D的方式来描述。 总结:G80将操作彻底标量化,内置128个1D标量SP,每个SP中有一个1D ALU,每周期处理一个1D操作,对于4D矢量操作,则将其拆分为4个1D标量操作。 R600仍采用SIMD架构,拥有64个SP,每个SP中有5个1D ALU,因而通常声称R600有320个PSU,每个SP只能处理一条指令,ATI采用VLIW体系将短指令集成为长的VLIW指令来提高资源利用率,例如5条1D标量指令可以被集成为一条VLIW指令送入SP中在一个周期完成。 第七章:G80与R600效能对比从前一章的讨论可以看出,R600的ALU规模64X5D=320明显比G80的128X1D=128要大,但是为何在实际的测试中,基于R600的RadeonHD2900XT并没有取得对G80/Geforce8800GTX的性能优势?本章将试图从两者流处理器设计差别上来寻找答案,对于纹理单元,ROP,显存带宽则不做重点讨论。 事实上,R600的显存带宽也要大于G80。 我们将从频率和执行效能两个方面来说明问题:1、频率:G80只拥有128个1D流处理器,在规模上处于绝对劣势,于是nVidia采用了shader频率与核心频率异步的方式来提高性能。 Geforce8800GTX虽然核心频率只有575MHZ,但shader频率却高达1375MHZ,即SP工作频率为核心频率的两倍以上,而R600则相对保守地采用了shader和核心同步的方式,在RadeonHD2900XT中,两者均为740MHZ。 这样一来,G80的shader频率几乎是R600的两倍,于是就相当于同频率下G80的SP数加倍达到256个,与R600的320个接近了很多。 在处理乘加(MADD)指令的时候,740MHZ的R600的理论峰值浮点运算速度为:740MHZ*64*5*2=473.6GFLOPS而shader频率为1350MHZ的G80的浮点运算速度为:1350MHZ*128*1*2=345.6GFLOPS,两者的差距并不像SP规模差距那么大。 2、执行效能:G80虽说shader频率很高,但由于数量差距悬殊,即使异步也无法补回理论运算速率的差距。 于是,要寻找答案,还要从两者流处理器的具体设计着手。 在G80中,每个矢量操作都会被拆分为1D标量操作来分配给不同的SP来处理,如果不考虑指令并行性等问题,G80在任何时刻,所有SP都是充分利用的。 而R600则没这么幸运,因为每个流处理器只能同时处理一条指令,因而R600要将短指令合并为能充分利用SP内5DALU运算资源的VLIW指令,但是这种合并并不是总能成功。 目前没有资料表明R600可以将指令拆开重组,也就是说,R600不能每时每刻都找到合适的指令拼接为5D指令来满载他的5D SP,这样的话我们假设处理纯4D指令的情况,不能拆分重组的话,R600每个SP只能处理一条4D指令,利用率80%,而对于G80,将指令拆开成1D操作,无论何时都能100%利用。 而且,R600的结构对编译器的要求很高,编译器必须尽可能寻找Shader指令中的并行性,并将其拼接为合适的长指令,而G80则只需简单拆分即可。 另外还需要说明的一点是,R600中每个SP的5个1D ALU并不是全功能的,据相关资料,每组5个ALU中,只有一个能执行函数运算,浮点运算和Multipy运算,但不能进行ADD运算,其余的4各职能执行MADD运算。 而G80的每个1D ALU是全功能的,这一点也在一定程度上影响了R600的效能。 总结:虽然R600的ALU规模远大于G80,但G80的SP运行频率几乎是R600的两倍,而且G80的体系架构采用完全标量化的计算,资源利用率更高,执行效能也更高,因而总体性能不落后于R600。 第八章:尴尬的中端--Geforce8600简析在新一代中端显卡中,最早发布也是最受关注的莫过于nVidia的G84---Geforce8600系列。 但是相比其高高在上的价格,它的性能表现实在不尽如人意,很多测试中均落后于价格低于它的老一代高端显卡Geforce7900GS。 本章将利用前面讨论的结论对G84核心的SP处理能力作简要地分析。 G84是G80核心的高度精简版本,SP数量从G80的128个锐减为32个,显存位宽也降为1/3--128bit。 抛开显存位宽和TMU ROP,我们着重看SP,G84的SP频率与核心频率也不相同,例如8600GT,核心频率只有540MHZ,shader频率却高达1242MHZ,即核心频率的两倍多,我们粗略按两倍记,则G84核心相当于核心shader同步的64(个1D标量) SP,而传统的VS和PS中ALU是4D的,于是可以说G84的计算能力相当于传统VS和PS总数为64/4=16的显卡,粗略比较,它与Geforce7600(PS+VS=17)的计算能力相近。 但当然,事实这样比较是有问题的,因为在G7X中,每个PS中有两个4D ALU,因而7600的运算能力高于传统PS+VS=17的显卡。 下面的计算就说明了问题:(MADD操作)对于7600GT ,VS为4D+1DPS为4D+4D核心频率560MHZ 理论峰值浮点运算速度:560MHZ*(12*(4+4)+5*(1+4))*2=135.52GFLOPS而对于8600GT:1242MHZ*32*1*2=79.4GFLOPS由此可见,8600GT的峰值运算速度甚至远低于上代的7600GT,更不用跟7900GS相比了。 但是,实际情况下,迫于传统架构所限,G7X满载的情况基本不可能出现,G7X的实际运算速率要远低于理论值,而对于G8X架构,执行效率则高很多,实际运算速率会更加接近理论极限。 而且支持SM4.0的G8X寄存器数目也要远多于G7X,众多效率优势,使得Geforce8600GT仅凭借少量的SP就足以击败上代中端7600GT。 但是作为DX10显卡,仅仅击败7600GT显然不是最终目标,仅32SP的它在计算量要求空前之高的DX10游戏中表现极差,根本不能满足玩家要求。 总结:8600GT性能上取代7600GT的目标凭借着高效的统一渲染架构总算勉强完成,但过少的SP数量使得其显然难以击败上代高端,更不用说流畅运行DX10游戏了,而高高在上的价位更使其处境不利,归根到底,nVidia对G84 SP数量的吝啬以及过高的价格定位造就了Geforce8600的尴尬,因此,就目前的情况来看,选用8600系列显然不如Geforce7900和RadeonX1950GT来的划算。
渲染管线与GPU(Shader前置知识)渲染管线是实时渲染的核心组件,其目的通过虚拟相机、三维物体、光源等生成二维画面。 它一般分为四个大阶段——应用阶段、几何运算、光栅化、像素运算。 应用阶段由应用程序驱动,主要任务包括用户输入处理、碰撞检测、动画、物理模拟、全局加速算法等,通常在CPU端执行。 这个阶段决定了渲染的效率,因此许多渲染优化,如各种剔除算法,都在此阶段进行。 部分应用阶段的工作可以通过Compute Shader交给GPU处理,实现GPU的高并行计算能力。 几何运算阶段负责处理形体变换、投影和其他逐顶点或逐三角面的几何操作,决定绘制对象是什么、如何绘制和绘制位置。 此阶段可以细分为顶点Shading阶段、投影阶段、剪裁阶段、屏幕映射阶段。 顶点Shading阶段负责顶点位置计算、输出法线、纹理坐标等信息。 几何运算阶段包含细分曲面、几何Shading和流输出等可选过程,这些过程在GPU中可以独立实现。 光栅化阶段将屏幕空间的二维顶点及其深度等数据转化到屏幕像素内,分为三角面设置(图素集合)阶段与三角形遍历阶段。 最后是像素运算阶段,通过前面所有阶段后,图素内的像素被传递到此阶段,进行深度测试和颜色确定。 此阶段分为像素Shading阶段与合并阶段,像素Shading阶段使用插值Shading数据作为输入,输出颜色传入合并阶段,而合并阶段负责将像素shading算出的颜色与当前颜色缓存的颜色进行混合。 渲染管线中,GPU的高并行计算能力通过流水线实现,将大量简单任务同时处理,从而大幅度提高了渲染效率。 通过细分曲面、几何Shading等可选过程,GPU能对模型进行优化,增加细节表现力。 同时,GPU在像素运算阶段提供高度可编程性,允许用户实现各种复杂的渲染效果,如纹理贴图、Alpha测试等。 综上所述,渲染管线与GPU紧密合作,通过高效的数据处理和并行计算,实现实时、高质量的三维图像渲染。 了解渲染管线的工作原理和GPU在其中的作用,对于掌握Shader技术、提高渲染效率至关重要。
栅格化图层(Rasterization Layer)是计算机图形学中的一个概念,用于描述将矢量图形转换为栅格(像素)图像的过程和结果。 在计算机图形学中,矢量图形是由基于数学公式的线条和曲线描述的,而栅格图像则是由像素(像素网格)组成的,每个像素具有特定的位置和颜色值。 栅格化图层是将矢量图形转换为栅格图像的过程,这通常是为了在显示设备上显示和处理图形。 栅格化图层的过程可以简单地描述为将矢量图形中的每个线条和曲线转换为像素,并根据需要对像素进行着色。 这个过程通常涉及到图形的光栅化(Rasterization)、抗锯齿(Anti-aliasing)和插值(Interpolation)等技术,以确保生成的栅格图像在显示设备上看起来平滑、清晰且细节丰富。 一旦图形被栅格化,就可以在计算机屏幕上进行渲染和显示,以及进行其他图形处理操作。 栅格化图层在计算机图形学中起到了重要的作用,它使得矢量图形能够以像素级别进行操作和呈现,以满足计算机图形的需求。 栅格化图层是将矢量图形转换为栅格图像的过程,而不是指存储栅格图像的特定数据结构或格式。 栅格图像可以使用不同的文件格式或编码方式进行存储,如JPEG、PNG、BMP等。 栅格化图层是在图形渲染过程中进行的中间步骤,用于生成最终的栅格图像。
光栅化与光线追踪,是渲染技术中的双剑,各自解决屏幕空间中的视觉呈现。 光栅化犹如像素级魔术师,通过透视投影,将3D模型分解为二维屏幕上的色彩拼图。 它的核心在于通过循环遍历像素,逐个检查与场景中物体的交点,填充每个像素的颜色,确保可见性(光栅化解决可见性:通过像素级射线追踪,计算与摄像机交点的最近物体)。
相比之下,光线追踪则是更细致的追踪过程,从每个像素出发,追踪光线与场景的交互,取交点的详细信息来决定像素颜色,即使可能与多个物体产生交点(光线追踪:追踪光线与场景物体交点,设置像素颜色)。 光栅化则先遍历场景的几何形状,然后才是像素层面的处理。
在算法上,光栅化简化为:顶点投射到屏幕,像素逐个检查在三角形内的归属,填充颜色(光栅化:投射三角形到屏幕,用透视投影,测试像素在2D三角形内填充颜色)。 而光线追踪则反之,从像素开始,计算与物体的交互。
在实际应用中,光栅化占据渲染时间的大部分,尤其是在早期图形游戏中。 虽然现代API通常自动处理这些细节,理解其工作原理对于性能优化和艺术效果至关重要。 光栅化过程涉及帧缓冲区的管理,通过深度缓冲(如Z-buffer)来确定遮挡和层次关系,确保图像的正确呈现。
深度缓冲是关键环节,它存储每个像素的深度值,通过比较新绘制的片段与当前深度,决定最终颜色,减少了对几何体深度排序的需求。 然而,这也有其挑战,如内存消耗和精度问题,需要权衡性能与视觉质量。
GPU使用高效算法,如压缩数据结构,加速深度测试和减少过度绘制,提高渲染效率。 现代GPU的优势体现在处理3D应用,尤其是生成清晰无锯齿的图像。
计算片段深度是通过屏幕空间的仿射映射,找到与视线相交点的深度值,这涉及到复杂的数学运算,如前向差分。 同时,视图空间的深度缓冲可能会导致精度问题,需要额外的缓冲策略来解决。

纹理处理是光栅化中的另一个重要部分,从纹理坐标映射到屏幕,通过纹理过滤(如双线性)确保颜色连续,减少锯齿。 Mipmapping则通过预计算纹理的多级细节,提供更平滑的视觉效果,是现代图形引擎的标准实践。
理解光栅化的纹理处理,包括纹理坐标的处理,如逐顶点属性和纹理坐标插值,对于创建真实感的图像至关重要。 从仿射与投影的差异、纹理扭曲,到早期游戏的近似处理,现代技术如逐顶点纹理坐标生成,都在不断演进。
最终,光栅化是图形渲染技术的基石,尽管看似复杂,但理解它的原理和优化策略,对于游戏开发者和图形设计者来说,都是提高作品质量的关键。 通过掌握这些核心概念,可以更好地利用现代硬件,创造令人惊叹的视觉效果。
内容声明:
1、本站收录的内容来源于大数据收集,版权归原网站所有!
2、本站收录的内容若侵害到您的利益,请联系我们进行删除处理!
3、本站不接受违法信息,如您发现违法内容,请联系我们进行举报处理!
4、本文地址:http://www.jujiwang.com/article/17a68280a54ed3b152d8.html,复制请保留版权链接!
在计算机图形的领域中,光栅化是一个至关重要的技术,它将复杂的向量图形转换为可显示在屏幕上的像素图像,这一过程是创造数字视觉奇观的基石,为我们提供了从电影到视频游戏再到虚拟现实体验中看到的逼真图像,什么是光栅化,光栅化是将矢量图形,由线段和曲线组成的,转换为位图的过程,位图是一幅图像,由网格状的像素,每个像素代表一个颜色,组成,光栅化算...。
本站公告 2024-10-01 18:26:28

简介跳一跳是一款非常有名的休闲游戏,这款游戏玩法简单,但是却非常考验玩家的耐心和手速,玩家需要控制一只青蛙在荷叶上跳跃,最终到达终点,如果你对跳一跳游戏已经玩腻了,那么你可以尝试自己编写一个自定义MOD,来增加游戏的乐趣,使用Python编写跳一跳MOD非常简单,只需要掌握一些基础的Python知识即可,编写MOD安装依赖库在编写MO...。
本站公告 2024-09-30 12:07:01
引言IronPython是一个开源实现,它允许在.NET框架中使用Python脚本语言,它将Python的动态和脚本能力与.NET的强大性和广泛的库相结合,为开发人员提供了强大的工具,可以自动化任务并高效地处理数据,IronPython的优势脚本自动化,IronPython使开发人员能够使用Python脚本编写自动化任务,例如文件处理...。
本站公告 2024-09-28 19:18:01

在JavaScript中,setTimeout,函数是一个非常有用的工具,它允许我们安排一个函数在指定的延迟后执行,这对于创建复杂的异步任务非常有用,这些任务需要在一段时间后执行或在特定事件发生后触发,基本用法setTimeout,函数的语法为,setTimeout,callback,delay,callback是要执行的函数,...。
最新资讯 2024-09-28 10:39:06

您正在寻找提高服务器性能的方法吗,本文将介绍一些技巧,帮助您充分利用RedHatEnterpriseLinux6.2,RHEL6.2,系统,1.优化内核参数内核参数控制着操作系统的底层行为,您可以通过调整某些参数来提高性能,例如,您可以,增加内存缓存大小,vm.min,free,kbytes和vm.max,free,kbytes,调整...。
互联网资讯 2024-09-25 12:34:41
简介Shelldeclare是Bash4及更高版本中引入的一个功能强大的工具,它允许开发者声明变量和定义其数据类型,这在编写健壮且可维护的脚本时至关重要,因为这有助于防止常见的数据类型错误,并提高脚本的可读性和可调试性,Shelldeclare语法Shelldeclare语法如下,```bashdeclare[,aAfFgilnrtu...。
互联网资讯 2024-09-23 13:28:55

Linux是一种流行的操作系统,以其稳定性、安全性、开源性和可定制性而闻名,如果您想学习如何使用Linux,那么使用视频教程是一个很好的方法,Linux视频教程的优势可视化学习,视频教程可以让您看到Linux命令和工具的实际操作,这比单纯阅读文档要容易得多,互动体验,您可以随时暂停、倒带或快进视频,还可以重新观看您不理解的部分,方便快...。
互联网资讯 2024-09-23 11:32:15

正无穷大,符号为∞,表示一个无限大的数,它大于任何实数,性质对于任何实数a,有a,∞=∞,对于任何实数a,有a,∞=,∞,对于任何正数a,有a×∞=∞,对于任何非零实数a,有a,∞=0,对于任何正数a,有∞,a=∞,应用正无穷大在数学、物理和工程等领域有广泛的应用,例如,在微积分中,极限可以是正无穷大或负无穷大,在物理中,正无穷大可以...。
本站公告 2024-09-23 02:20:49
body,font,family,Arial,Helvetica,sans,serif,font,size,16px,line,height,1.5,color,333,h1,font,size,24px,font,weight,bold,margin,bottom,16px,h2,font,size,20px,font,weig...。
技术教程 2024-09-14 21:05:31

在当今竞争激烈的商业环境中,提升品牌知名度至关重要,一个知名且广受认同的品牌可以吸引更多的客户、增加销量并建立忠诚度,除了...。
最新资讯 2024-09-10 22:08:21

Java是当今最流行的编程语言之一,它具有许多特性,使其成为开发企业级应用程序的理想选择,手动安装Java可能是一项耗时的任务,尤其是在需要在多个系统上安装时,幸运的是,有许多工具和技术可以帮助您自动化Java安装过程,在本文中,我们将探讨其中一些工具和方法,以帮助您简化安装过程,使用脚本使用脚本自动化Java安装的一种简单方法是编写...。
本站公告 2024-09-06 17:46:29

飞碟,UFO,的研究是一个长期以来一直吸引着科学界、政府机构和公众的迷人话题,近年来,随着新技术和目击事件的出现,UFO研究领域出现了许多令人兴奋的发展,了人类在航空航天领域的重大进步,自然现象,一些研究人员认为,UFO目击事件是由自然现象,例如天气气球、流星或大气湍流造成的错误识别,心理因素,还有一些理论表明,UFO目击事件可能是由...。
互联网资讯 2024-09-04 03:50:07