(换肤)
语言:

文章编号:11308时间:2024-09-30人气:
AWStats 是一款免费且开源的 Web 服务器日志分析工具,可为网站管理员提供有关网站访问者行为的宝贵见解。
通过分析 Web 服务器日志文件,AWStats 可以生成易于理解的报告,其中包含有关以下内容的信息:
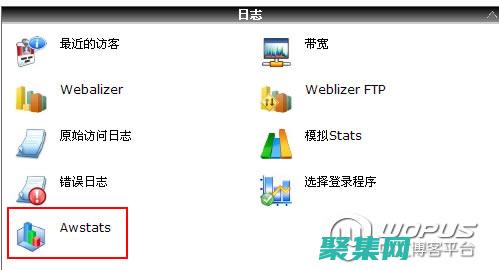
AWStats 报告由多个部分组成,每个部分提供不同类型的见解。
概览部分提供了网站流量的总体摘要,包括访客数量、访问次数、每位访客的页面浏览量以及平均停留时间。
“按日期”
今天安装了awstats(AWStats是在Sourceforge上发展很快的一个基于Perl的WEB日志分析工具。 ),好好折腾了一把,终于搞完了,参考了不少资料,将主要步骤和遇到的问题分享一下。
1.在home下建一个目录awstats,cd /home/awstats
下载awstats最新版本7.0
3.安装
复制代码
代码如下:
[root@JMAppSer tools]# perl awstats_
----- AWStats awstats_configure 1.0 (build 1.9) (c) Laurent Destailleur -----
This tool will help you to configure AWStats to analyze statistics for
one web server. You can Try to use it to let it do all that is possible
in AWStats setup, however following the step by step manual setup
documentation (docs/) is often a better idea. Above all if:
- You are not an administrator user,
- You want to analyze downloaded log files without web server,
- You want to analyze mail or ftp log files instead of web log files,
- You need to analyze load balanced servers log files,
- You want to understand all possible ways to use AWStats...
Read the AWStats documentation (docs/).
----- Running OS detected: Linux, BSD or Unix
----- Check for web server install
Found Web server Apache config file /usr/local/apache/conf/
----- Check and complete web server config file /usr/local/apache/conf/
Add Alias /awstatsclasses /usr/local/awstats/wwwroot/classes/
Add Alias /awstatscss /usr/local/awstats/wwwroot/css/
Add Alias /awstatsicons /usr/local/awstats/wwwroot/icon/
Add ScriptAlias /awstats/ /usr/local/awstats/wwwroot/cgi-bin/
Add Directory directive
AWStats directives added to Apache config file.
----- Update model config file /usr/local/awstats/wwwroot/cgi-bin/
File updated.
----- Need to create a new config file ?
Do you want me to build a new AWStats config/profile
file (required if First install) [y/N] ? y
----- Define config file name to create
What is the name of your web site or profile analysis ?
Example: demo
Your web site, virtual server or profile name:
----- Define config file path
In which directory do you plan to store your config file(s) ?
Default: /etc/awstats
Directory path to store config file(s) (Enter for default):
/usr/local/awstats/config
----- Create config file /usr/local/awstats/config/
Config file /usr/local/awstats/config/ created.
----- Restart Web server with /sbin/service httpd restart
Usage: /etc/init.d/httpd [-D name] [-d directory] [-f file]
[-C directive] [-c directive]
[-k start|restart|graceful|graceful-stop|stop]
[-v] [-V] [-h] [-l] [-L] [-t] [-S]
-D name : define a name for use in IfDefine name directives
-d directory : specify an alternate initial ServerRoot
-f file : specify an alternate ServerConfigFile
-C directive : process directive before reading config files
-c directive : process directive after reading config files
-e level : show startup errors of level (see LogLevel)
-E file : log startup errors to file
-v : show version number
-V : show compile settings
-h : list available command line options (this page)
-l : list compiled in modules
-L : list available configuration directives
-t -D DUMP_VHOSTS : show parsed settings (currently only vhost settings)
-S : a synonym for -t -D DUMP_VHOSTS
-t -D DUMP_MODULES : show all loaded modules
-M : a synonym for -t -D DUMP_MODULES
-t : run syntax check for config files
----- Add update process inside a scheduler
Sorry, does not support automatic add to cron yet.
You can do it manually by adding the following command to your cron:
/usr/local/awstats/wwwroot/cgi-bin/ -update -config=
Or if you have several config files and prefer having only one command:
/usr/local/awstats/tools/awstats_ now
Press ENTER to continue...
A SIMPLE config file has been created: /usr/local/awstats/config/
You should have a look inside to check and change manually main parameters.
You can then manually update your statistics for with command:
perl -update -config=
You can also read your statistics for with URL:
Press ENTER to finish...
[root@JMAppSer tools]# cp /usr/loca/awstats/wwwroot/icon /usr/local/apache/htdocs/awstatsicons -rf
cp: 无法 stat “/usr/loca/awstats/wwwroot/icon”: 没有那个文件或目录
[root@JMAppSer tools]#
[root@JMAppSer tools]#
[root@JMAppSer tools]# ls
awstats_ awstats_ geoip_ nginx webmin
awstats_ awstats_ httpd_conf xslt
[root@JMAppSer tools]# cd ..
[root@JMAppSer awstats]# ls
awstats-7.0 awstats-7.1 config docs tools wwwroot
[root@JMAppSer awstats]# ll
总计 1508
drwxr-xr-x 5 1000 1000 4096 2010-12-06 awstats-7.0
drwxr-xr-x 5 root root 4096 11-22 17:52 awstats-7.1
-rw-r--r-- 1 root root 11-22 18:02
drwxr-xr-x 2 root root 4096 11-25 10:21 config
drwxr-xr-x 4 root root 4096 11-22 18:04 docs
-rw-r--r-- 1 root root 6787 11-22 18:04
drwxr-xr-x 5 root root 4096 11-22 18:04 tools
drwxr-xr-x 7 root root 4096 11-22 18:04 wwwroot
[root@JMAppSer awstats]# cd wwwroot/
[root@JMAppSer wwwroot]# ls
cgi-bin classes css icon js
[root@JMAppSer wwwroot]# cp icon/ /usr/local/jiemai/apache-blogs/htdocs/awstatsicons -rf
[root@JMAppSer wwwroot]#
[root@JMAppSer wwwroot]#
[root@JMAppSer wwwroot]# pwd
/usr/local/awstats/wwwroot
[root@JMAppSer wwwroot]# cd ..
[root@JMAppSer awstats]# ls
awstats-7.0 awstats-7.1 config docs tools wwwroot
[root@JMAppSer awstats]# ls
awstats-7.0 awstats-7.1 config docs tools wwwroot
[root@JMAppSer awstats]# ll
总计 1508
drwxr-xr-x 5 1000 1000 4096 2010-12-06 awstats-7.0
drwxr-xr-x 5 root root 4096 11-22 17:52 awstats-7.1
-rw-r--r-- 1 root root 11-22 18:02
drwxr-xr-x 2 root root 4096 11-25 10:21 config
drwxr-xr-x 4 root root 4096 11-22 18:04 docs
-rw-r--r-- 1 root root 6787 11-22 18:04
drwxr-xr-x 5 root root 4096 11-22 18:04 tools
drwxr-xr-x 7 root root 4096 11-22 18:04 wwwroot
[root@JMAppSer awstats]# cd config/
[root@JMAppSer config]# ls
[root@JMAppSer config]# vi
# AWSTATS CONFIGURE FILE 7.0
# Copy this file into and edit this new config file
# to setup AWStats (See documentation in docs/ directory).
# The config file must be in /etc/awstats, /usr/local/etc/awstats or /etc (for
# Unix/Linux) or same directory than (Windows, Mac, Unix/Linux...)
# To include an environment variable in any parameter (AWStats will replace
# it with its value when reading it), follow the example:
# Parameter=__ENVNAME__
# Note that environment variable AWSTATS_CURRENT_CONFIG is always defined with
# the config value in an AWStats running session and can be used like others.
# $Revision: 1.353 $ - $Author: eldy $ - $Date: 2012/02/15 14:19:22 $
# MAIN SETUP SECTION (Required to make AWStats work)
# LogFile contains the web, ftp or mail server log file to analyze.
# Possible values: A full path, or a relative path from directory.
# Example: /var/log/apache/
# Example: ../logs/
# You can also use tags in this filename if you need a dynamic file name
# depending on date or time (Replacement is made by AWStats at the beginning
# of its execution). This is available tags :
# %YYYY-n is replaced with 4 digits year we were n hours ago
# %YY-n is replaced with 2 digits year we were n hours ago
# %MM-n is replaced with 2 digits month we were n hours ago
# %MO-n is replaced with 3 letters month we were n hours ago
# %DD-n is replaced with day we were n hours ago
# %HH-n is replaced with hour we were n hours ago
# %NS-n is replaced with number of seconds at 00:00 since 1970
# %WM-n is replaced with the week number in month (1-5)
# %Wm-n is replaced with the week number in month (0-4)
# %WY-n is replaced with the week number in year (01-52)
# %Wy-n is replaced with the week number in year (00-51)
# %DW-n is replaced with the day number in week (1-7, 1=sunday)
# use n=24 if you need (1-7, 1=monday)
# %Dw-n is replaced with the day number in week (0-6, 0=sunday)
# use n=24 if you need (0-6, 0=monday)
# Use 0 for n if you need current year, month, day, hour...
# Example: /var/log/access_log.%YYYY-0%MM-0%
# Example: C:/WINNT/system32/LogFiles/W3SVC1/ex%YY-24%MM-24%
# You can also use a pipe if log file come from a pipe :
# Example: gzip -d /var/log/apache/ |
# If there are several log files from load balancing servers :
# Example: /pathtotools/ * |
#LogFile=/var/log/httpd/
LogFile=/usr/local/jiemai/apache-blogs/logs/access_logs
# Note: Result of DNS Lookup can be used to build the Country report. However
# it is highly recommanded to enable the plugin geoip or geoipfree to
# have an accurate Country report with no need of DNS Lookup.
# Possible values:
# 0 - No DNS Lookup
# 1 - DNS Lookup is fully enabled
# 2 - DNS Lookup is made only from static DNS cache file (if it exists)
# Default: 2
DNSLookup=2
# When AWStats updates its statistics, it stores results of its analysis in
# files (AWStats
# Relative or absolute web URL of your awstats cgi-bin directory.
# This parameter is used only when AWStats is run from command line
# with -output option (to generate links in HTML reported page).
# Example: /awstats
# Default: /cgi-bin (means is in /yourwwwroot/cgi-bin)
DirCgi=/usr/local/awstats/wwwroot/cgi-bin
/AllowToUpdateStatsFromBrowser
# When this parameter is set to 1, AWStats adds a button on report page to
# allow to update statistics from a web browser. Warning, when update is
# made from a browser, AWStats is run as a CGI by the web server user defined
# in your web server (user nobody by default with Apache, IUSR_XXX with
# IIS), so the DirData directory and all already existing history files
# awstatsMMYYYY[] must be writable by this user. Change permissions if
# necessary to Read/Write (and Modify for Windows NTFS file systems).
# Warning: Update process can be long so you might experience time out
# browser errors if you dont launch AWStats frequently enough.
# When set to 0, update is only made when AWStats is run from the command
# line interface (or a task scheduler).
# Possible values: 0 or 1
# Default: 0
AllowToUpdateStatsFromBrowser=1
# AWStats saves and sorts its target=_blank> 1557L, C written
[root@JMAppSer config]# chown -R root:root /usr/local/awstats
[root@JMAppSer config]# chmod -R 755 /usr/local/awstats
[root@JMAppSer config]# mkdir /usr/local/awstats/data
[root@JMAppSer config]# chown /usr/local/awstats/data
[root@JMAppSer config]# chmod 777
DirData=/usr/local/awstats/data
DirCgi=/usr/local/awstats/wwwroot/cgi-bin
AllowToUpdateStatsFromBrowser=1
6.设置权限
chown -R root:root /usr/local/awstats
chmod -R 755 /usr/local/awstats
mkdir /usr/local/awstats/data
chown /usr/local/awstats/data
chmod 777 data
chmod 755 /usr/local/awstats/wwwroot/cgi-bin/*
7.生成分析日志与静态查看界面
cd /usr/local/awstats/wwwroot/cgi-bin
perl -config=上面域名 -update -lang=cn
perl -config=上面域名 -output -staticlinks -lang=cnawstats.上面
8.测试 http:// 上面的域名/awstats/?config=上面的域名
遇到的问题:
-config=上面域名 -update -lang=cn提示出错,或在测试时提示出错。LogFormat不正确:
原因:access_logs格式不正确,删除access_logs,重启APACHE。搞定
2.测试时看图片显示不了。
原因:/etc/awstats/awstats.上面输入的中的DirIcons配置不正确,这个目录一定要从/usr/local/apache/htdocs目录开始算,相对目录,要确保配置的目录可能过http访问到
3.点击测试页面的“立即更新”时,提示无法存储
原因:/usr/local/awstats/data的权限不正确,需要使用nobody权限,赋777.
手工识别和拒绝爬虫的访问相当多的爬虫对网站会造成非常高的负载,因此识别爬虫的来源IP是很容易的事情。 最简单的办法就是用netstat检查80端口的连接:netstat -nt | grep youhostip:80 | awk {print $5} | awk -F: {print $1}| sort | uniq -c | sort -r -n 这行shell可以按照80端口连接数量对来源IP进行排序,这样可以直观的判断出来网页爬虫。 一般来说爬虫的并发连接非常高。 如果使用lighttpd做Web Server,那么就更简单了。 lighttpd的mod_status提供了非常直观的并发连接的信息,包括每个连接的来源IP,访问的URL,连接状态和连接时间等信息,只要检查那些处于handle-request状态的高并发IP就可以很快确定爬虫的来源IP了。 拒绝爬虫请求既可以通过内核防火墙来拒绝,也可以在web server拒绝,比方说用iptables拒绝:iptables -A INPUT -i eth0 -j Drop -p tcp --dport 80 -s 84.80.46.0/24直接封锁爬虫所在的C网段地址。 这是因为一般爬虫都是运行在托管机房里面,可能在一个C段里面的多台服务器上面都有爬虫,而这个C段不可能是用户宽带上网,封锁C段可以很大程度上解决问题。 通过识别爬虫的User-Agent信息来拒绝爬虫有很多爬虫并不会以很高的并发连接爬取,一般不容易暴露自己;有些爬虫的来源IP分布很广,很难简单的通过封锁IP段地址来解决问题;另外还有很多各种各样的小爬虫,它们在尝试google以外创新的搜索方式,每个爬虫每天爬取几万的网页,几十个爬虫加起来每天就能消耗掉上百万动态请求的资源,由于每个小爬虫单独的爬取量都很低,所以你很难把它从每天海量的访问IP地址当中把它准确的挖出来。 这种情况下我们可以通过爬虫的User-Agent信息来识别。 每个爬虫在爬取网页的时候,会声明自己的User-Agent信息,因此我们就可以通过记录和分析User-Agent信息来挖掘和封锁爬虫。 我们需要记录每个请求的User-Agent信息,对于Rails来说我们可以简单的在app/controllers/里面添加一个全局的before_filter,来记录每个请求的User-Agent信息 HTTP_USER_AGENT #{[HTTP_USER_AGENT]}然后统计每天的,抽取User-Agent信息,找出访问量最大的那些User-Agent。 要注意的是我们只关注那些爬虫的User-Agent信息,而不是真正浏览器User-Agent,所以还要排除掉浏览器User-Agent,要做到这一点仅仅需要一行shell:grep HTTP_USER_AGENT | grep -v -E MSIE|Firefox|Chrome|Opera|Safari|Gecko | sort | uniq -c | sort -r -n | head -n 100 > 统计结果类似这样: HTTP_USER_AGENT Baiduspider+(+HTTP_USER_AGENT Mozilla/5.0 (compatible; Googlebot/2.1; +HTTP_USER_AGENT Mediapartners-Google HTTP_USER_AGENT msnbot/2.0b (+从日志就可以直观的看出每个爬虫的请求次数。 要根据User-Agent信息来封锁爬虫是件很容易的事情,lighttpd配置如下:$HTTP[useragent] =~ qihoobot|^Java|Commons-HttpClient|Wget|^PHP|Ruby|Python { = ( ^/(.*) => / )}使用这种方式来封锁爬虫虽然简单但是非常有效,除了封锁特定的爬虫,还可以封锁常用的编程语言和HTTP类库的User-Agent信息,这样就可以避免很多无谓的程序员用来练手的爬虫程序对网站的骚扰。 还有一种比较常见的情况,就是某个搜索引擎的爬虫对网站爬取频率过高,但是搜索引擎给网站带来了很多流量,我们并不希望简单的封锁爬虫,仅仅是希望降低爬虫的请求频率,减轻爬虫对网站造成的负载,那么我们可以这样做:$HTTP[user-agent] =~ Baiduspider+ {-seconds = 10}对网络的爬虫请求延迟10秒钟再进行处理,这样就可以有效降低爬虫对网站的负载了。 通过网站流量统计系统和日志分析来识别爬虫有些爬虫喜欢修改User-Agent信息来伪装自己,把自己伪装成一个真实浏览器的User-Agent信息,让你无法有效的识别。 这种情况下我们可以通过网站流量系统记录的真实用户访问IP来进行识别。 主流的网站流量统计系统不外乎两种实现策略:一种策略是在网页里面嵌入一段js,这段js会向特定的统计服务器发送请求的方式记录访问量;另一种策略是直接分析服务器日志,来统计网站访问量。 在理想的情况下,嵌入js的方式统计的网站流量应该高于分析服务器日志,这是因为用户浏览器会有缓存,不一定每次真实用户访问都会触发服务器的处理。 但实际情况是,分析服务器日志得到的网站访问量远远高于嵌入js方式,极端情况下,甚至要高出10倍以上。 现在很多网站喜欢采用awstats来分析服务器日志,来计算网站的访问量,但是当他们一旦采用Google Analytics来统计网站流量的时候,却发现GA统计的流量远远低于awstats,为什么GA和awstats统计会有这么大差异呢?罪魁祸首就是把自己伪装成浏览器的网络爬虫。 这种情况下awstats无法有效的识别了,所以awstats的统计数据会虚高。 其实作为一个网站来说,如果希望了解自己的网站真实访问量,希望精确了解网站每个频道的访问量和访问用户,应该用页面里面嵌入js的方式来开发自己的网站流量统计系统。 自己做一个网站流量统计系统是件很简单的事情,写段服务器程序响应客户段js的请求,分析和识别请求然后写日志的同时做后台的异步统计就搞定了。 通过流量统计系统得到的用户IP基本是真实的用户访问,因为一般情况下爬虫是无法执行网页里面的js代码片段的。 所以我们可以拿流量统计系统记录的IP和服务器程序日志记录的IP地址进行比较,如果服务器日志里面某个IP发起了大量的请求,在流量统计系统里面却根本找不到,或者即使找得到,可访问量却只有寥寥几个,那么无疑就是一个网络爬虫。 分析服务器日志统计访问最多的IP地址段一行shell就可以了:grep Processing | awk {print $4} | awk -F. {print $1.$2.$3.0} | sort | uniq -c | sort -r -n | head -n 200 > stat_然后把统计结果和流量统计系统记录的IP地址进行对比,排除真实用户访问IP,再排除我们希望放行的网页爬虫,比方Google,网络,微软msn爬虫等等。 最后的分析结果就就得到了爬虫的IP地址了。 以下代码段是个简单的实现示意:whitelist = [](#{RAILS_ROOT}/lib/) { |line| whitelist << [0] if line }realiplist = [](#{RAILS_ROOT}/log/visit_) { |line|realiplist << if line }iplist = [](#{RAILS_ROOT}/log/stat_) do |line|ip = [1] << ip if [0]_i > 3000 && !?(ip) && !?(ip)end _crawler(iplist)分析服务器日志里面请求次数超过3000次的IP地址段,排除白名单地址和真实访问IP地址,最后得到的就是爬虫IP了,然后可以发送邮件通知管理员进行相应的处理。 网站的实时反爬虫防火墙实现策略通过分析日志的方式来识别网页爬虫不是一个实时的反爬虫策略。 如果一个爬虫非要针对你的网站进行处心积虑的爬取,那么他可能会采用分布式爬取策略,比方说寻找几百上千个国外的代理服务器疯狂的爬取你的网站,从而导致网站无法访问,那么你再分析日志是不可能及时解决问题的。 所以必须采取实时反爬虫策略,要能够动态的实时识别和封锁爬虫的访问。 要自己编写一个这样的实时反爬虫系统其实也很简单。 比方说我们可以用memcached来做访问计数器,记录每个IP的访问频度,在单位时间之内,如果访问频率超过一个阀值,我们就认为这个IP很可能有问题,那么我们就可以返回一个验证码页面,要求用户填写验证码。 如果是爬虫的话,当然不可能填写验证码,所以就被拒掉了,这样很简单就解决了爬虫问题。 用memcache记录每个IP访问计数,单位时间内超过阀值就让用户填写验证码,用Rails编写的示例代码如下:ip_counter = (_ip)if !ip_(_ip, 1, :expires_in => )elsif ip_counter > 2000render :template => test, :status => 401 and return falseend这段程序只是最简单的示例,实际的代码实现我们还会添加很多判断,比方说我们可能要排除白名单IP地址段,要允许特定的User-Agent通过,要针对登录用户和非登录用户,针对有无referer地址采取不同的阀值和计数加速器等等。 此外如果分布式爬虫爬取频率过高的话,过期就允许爬虫再次访问还是会对服务器造成很大的压力,因此我们可以添加一条策略:针对要求用户填写验证码的IP地址,如果该IP地址短时间内继续不停的请求,则判断为爬虫,加入黑名单,后续请求全部拒绝掉。 为此,示例代码可以改进一下:before_filter :ip_firewall, :except => :testdef ip_firewallrender :file => #{RAILS_ROOT}/public/, :status => 403 if ?(ip_sec)end我们可以定义一个全局的过滤器,对所有请求进行过滤,出现在黑名单的IP地址一律拒绝。 对非黑名单的IP地址再进行计数和统计:ip_counter = (_ip)if !ip_(_ip, 1, :expires_in => )elsif ip_counter > 2000crawler_counter = (crawler/#{_ip})if !crawler_(crawler/#{_ip}, 1, :expires_in => )elsif crawler_counter > (ip_sec)render :file => #{RAILS_ROOT}/public/, :status => 403 and return falseendrender :template => test, :status => 401 and return falseend如果某个IP地址单位时间内访问频率超过阀值,再增加一个计数器,跟踪他会不会立刻填写验证码,如果他不填写验证码,在短时间内还是高频率访问,就把这个IP地址段加入黑名单,除非用户填写验证码激活,否则所有请求全部拒绝。 这样我们就可以通过在程序里面维护黑名单的方式来动态的跟踪爬虫的情况,甚至我们可以自己写个后台来手工管理黑名单列表,了解网站爬虫的情况。 关于这个通用反爬虫的功能,我们开发一个开源的插件:这个策略已经比较智能了,但是还不够好!我们还可以继续改进:1、用网站流量统计系统来改进实时反爬虫系统还记得吗?网站流量统计系统记录的IP地址是真实用户访问IP,所以我们在网站流量统计系统里面也去操作memcached,但是这次不是增加计数值,而是减少计数值。 在网站流量统计系统里面每接收到一个IP请求,就相应的(key)。 所以对于真实用户的IP来说,它的计数值总是加1然后就减1,不可能很高。 这样我们就可以大大降低判断爬虫的阀值,可以更加快速准确的识别和拒绝掉爬虫。 2、用时间窗口来改进实时反爬虫系统爬虫爬取网页的频率都是比较固定的,不像人去访问网页,中间的间隔时间比较无规则,所以我们可以给每个IP地址建立一个时间窗口,记录IP地址最近12次访问时间,每记录一次就滑动一次窗口,比较最近访问时间和当前时间,如果间隔时间很长判断不是爬虫,清除时间窗口,如果间隔不长,就回溯计算指定时间段的访问频率,如果访问频率超过阀值,就转向验证码页面让用户填写验证码。 最终这个实时反爬虫系统就相当完善了,它可以很快的识别并且自动封锁爬虫的访问,保护网站的正常访问。 不过有些爬虫可能相当狡猾,它也许会通过大量的爬虫测试来试探出来你的访问阀值,以低于阀值的爬取速度抓取你的网页,因此我们还需要辅助第3种办法,用日志来做后期的分析和识别,就算爬虫爬的再慢,它累计一天的爬取量也会超过你的阀值被你日志分析程序识别出来。
1.通过awstats分析apache日志(或者NGINX日志,含使用代理日志分析)2.借助GEOIP分析到国家名称3.借助和QQ纯真IP库分析IP所在中国的具体区域!
AWStats是在Sourceforge上发展很快的一个基于Perl的WEB日志分析工具。
Awstats是一个功能强大且个性化的免费网站日志分析工具,特别适合于深入了解您网站的流量和用户行为。它能够提供详尽的数据统计,包括:
总之,Awstats是一个全面且易于使用的工具,能够为您的网站运营和优化提供强大的数据支持。
内容声明:
1、本站收录的内容来源于大数据收集,版权归原网站所有!
2、本站收录的内容若侵害到您的利益,请联系我们进行删除处理!
3、本站不接受违法信息,如您发现违法内容,请联系我们进行举报处理!
4、本文地址:http://www.jujiwang.com/article/ea1938b879b8baf928f4.html,复制请保留版权链接!

简介DataGrid控件是许多应用程序中常用的功能,它允许用户查看和选择数据集中的行,DataGrid提供了多种行选择机制,以满足不同应用程序的需求,本文档将提供有关DataGrid行选择机制的详细指南,单行选择单行选择是最简单的选择机制,它允许用户一次只选择一行,要启用单行选择,请将DataGrid的`SelectionMode`属...。
本站公告 2024-09-29 18:50:36

在PHP中,四舍五入是一个常见的操作,但如果处理不当,可能会导致意外的结果,为什么四舍五入会出现问题,PHP中四舍五入最常见的陷阱源于浮点运算误差,浮点运算是一种近似计算,可能会导致微小的误差,从而影响四舍五入的结果,避免陷阱的方法1.使用PHP的内置函数PHP提供了一系列内置函数用于四舍五入,这些函数可以处理浮点运算误差,`roun...。
本站公告 2024-09-23 11:20:07

概述当Vue组件被创建时,它会经历一个称为生命周期的过程,生命周期是一系列钩子函数,允许您在组件的不同阶段执行特定操作,本文将重点介绍两个关键的生命周期钩子,`mounted`和`updated`,Mounted钩子`mounted`钩子在组件首次挂载到DOM时调用,此时,组件的DOM元素已经创建并且可以访问,何时使用您可以使用`mo...。
本站公告 2024-09-16 14:12:49

枚举窗口是一种遍历所有或特定一组窗口的方法,在WindowsAPI中,EnumChildWindows函数用于枚举指定父窗口的所有子窗口,而EnumWindows函数用于枚举整个系统中的所有顶级窗口,hWndChildAfter参数EnumChildWindows函数的hWndChildAfter参数指定枚举从哪个子窗口开始,它可以是...。
互联网资讯 2024-09-15 23:43:58

群策群力,后台管理系统提升团队协作的利器前言在当今飞速发展的数字时代,团队协作对于企业的成功至关重要,后台管理系统作为一种集中的平台,能够有效提升团队协作效率,实现知识管理,促进业务增长,本文将深入探讨后台管理系统在群策群力方面的优势,为企业提供切实可行的解决方案,一、集中化文件和资源管理后台管理系统最主要的优势之一在于其能够提供一个...。
本站公告 2024-09-15 18:41:06
03cul>,语法易学,Dart的语法与其他流行语言,如Java和JavaScript,相似,使得开发人员很容易上手,类型安全,Dart的类型系统有助于防止错误,提高代码质量和可维护性,高性能,Dart编译为高效的本机代码,提供出色的性能,跨平台,Dart应用程序可以在各种平台上运行,为开发人员提供更大的灵活性,丰富的生态系统,D...。
技术教程 2024-09-13 15:41:56

你是否曾经想知道互联网上庞大的信息是如何收集和组织的呢,这就是爬虫程序发挥作用的地方,爬虫程序是自动化软件,可以从网络上抓取和提取数据,为我们提供对网络背后宝藏的访问权限,爬虫程序的工作原理爬虫程序的工作方式类似于蜘蛛网,它们从一个起点开始,通常是某个网站的主页,它们会提取页面上的链接并将其添加到队列中,爬虫程序会跟随队列中的链接,抓...。
最新资讯 2024-09-12 23:04:15

简介小程序支付回调是小程序开发中非常重要的一个环节,通过回调,开发者可以获取到支付结果并进行相应的处理,本文将详细介绍小程序支付回调的各个方面,包括回调流程、回调参数、回调处理以及常见问题解决,回调流程小程序支付回调的流程如下,用户发起小程序支付请求支付成功后,微信支付服务器会向小程序服务器发送支付结果通知小程序服务器收到支付结果通知...。
互联网资讯 2024-09-11 01:19:45

欢迎来到单片机C语言编程的循序渐进之旅!文章专为初学者设计,将带你踏上令人振奋的嵌入式系统编程之旅,什么是单片机,单片机是一种小型的计算机,专门嵌入在设备中,以控制其功能,它们通常用于微控制器、传感器和执行特定任务的家用电器中,为什么选择C语言,C语言是一种低级语言,非常适合单片机编程,它提供了对硬件的精确控制,同时仍然易于学习和使用...。
技术教程 2024-09-10 08:01:07

在当今快节奏的物联网,IoT,时代,设备的连接性和功能至关重要,嵌入式Linux驱动程序在增强设备能力方面发挥着关键作用,使其能够与传感器、外围设备和网络连接,在本指南中,我们将探索如何利用嵌入式Linux驱动程序设计来提升您的设备功能,嵌入式Linux驱动程序概述嵌入式Linux驱动程序是软件组件,用于在嵌入式Linux系统与硬件设...。
互联网资讯 2024-09-09 13:07:07

汶川地震是一场毁灭性的自然灾害,造成数万人死亡,除了巨大的损失和痛苦之外,地震还留下了一些令人不安的证据,让人们不禁怀疑超自然现象的可能性,异象和预兆据报道,在2008年5月12日地震前几周,人们看到了奇怪的天文现象,如火球和流星雨,一些动物表现出了异常行为,例如蛇爬出地洞,鱼从水池中跳出,有传言称,有人在梦中看到了地震,并得到了关于...。
互联网资讯 2024-09-05 05:45:52

真实的恐惧,中国十大真实发生的灵异事件揭秘,真实的恐惧2,导语,灵异事件,一直是人们津津乐道的话题,虽然科学无法证明其真实性,但民间流传的众多故事却令人毛骨悚然,今天,我们就来为大家揭秘中国历史上十大真实的灵异事件,带你领略真实的恐惧,1.北京故宫,午门现鬼头,北京故宫,这座见证了中国历史兴衰的恢弘建筑,也流传着不少灵异故事,其中最著...。
互联网资讯 2024-09-04 01:15:08