(换肤)
语言:

文章编号:11494时间:2024-10-01人气:

Hadoop 分布式文件系统 (HDFS) 是 Hadoop 生态系统中的一个核心组件。它是一个分布式文件存储系统,用于在 Hadoop 集群中存储和管理海量数据。
HDFS 旨在高度容错、可扩展和可靠,使其成为处理大型数据集的理想解决方案。
HDFS 由两个主要组件组成:NameNode 和 DataNode。
NameNode 是 HDFS 的全局命名空间管理器。它负责管理 HDFS 中的所有文件和目录,并跟踪文件在 DataNode 上的位置。
DataNode 是 HDFS 数据存储的分布式服务器。它们存储实际的数据块,并负责处理客户端请求。
HDFS 与其他 Hadoop 组件紧密集成,创建了一个功能强大的生态系统,用于处理大数据。
MapReduce 是 Hadoop 生态系统中用于分布式处理大数据集的框架。HDFS 是 MapReduce 框架的基础,它提供数据存储和管理。
MapReduce 作业将数据块从 HDFS 读取到计算节点,进行处理,然后将结果写入回 HDFS。
Yarn 是 Hadoop 生态系统中的资源管理系统。它负责管理 Hadoop 集群中的资源,包括 CPU、内存和存储。
HDFS 与 Yarn 集成,允许 Yarn 为 MapReduce 作业和其他 Hadoop 应用程序分配资源。
HBase 是 Hadoop 生态系统中面向列的 NoSQL 数据库。它利用 HDFS 作为其底层存储系统,提供对数据的快速和灵活访问。
HBase 使用 HDFS 存储其数据表,并通过 Hadoop 生态系统中的其他组件进行管理和分析。
Hive 是 Hadoop 生态系统中用于数据仓库的工具。它提供了一种使用类 SQL 查询语言对 HDFS 中存储的数据进行查询和分析的方法。
Hive 与 HDFS 集成,使其能够直接从 HDFS 中读取和写入数据。
Spark 是 Hadoop 生态系统中用于分布式计算的框架。它提供了比 MapReduce 更快的内存计算引擎,并以交互式方式支持对数据的探索和分析。
Spark 与 HDFS 集成,使其能够读取和写入 HDFS 中的数据。
HDFS 在 Hadoop 生态系统中扮演着至关重要的角色。它提供了一个可靠且可扩展的数据存储平台,支持 Hadoop 生态系统中各种组件的分布式处理、分析和存储。
通过与其他 Hadoop 组件的紧密集成,HDFS 使组织能够有效地管理和处理海量数据集,从而获得有价值的见解并做出明智的决策。
Hadoop三个组件的关系是紧密相连、协同工作的,它们共同构成了Hadoop分布式计算框架的基石,这三个组件分别是:HDFS(Hadoop Distributed File System)、MapReduce和YARN(Yet Another Resource Negotiator)。 首先,HDFS是Hadoop的文件存储系统,它提供了一个高度可扩展的分布式文件系统,用于在低成本硬件上存储大量数据。 HDFS的设计特点使其能够处理PB级别的数据,并通过数据冗余机制保证数据的可靠性。 在Hadoop框架中,HDFS扮演着数据的“仓库”角色,它负责数据的存储和管理,为后续的数据处理和分析提供稳定的数据基础。 其次,MapReduce是Hadoop的数据处理引擎,它负责大数据的计算和分析工作。 MapReduce编程模型简洁而强大,允许用户编写两个主要函数:Map函数和Reduce函数,用于处理和分析存储在HDFS中的大规模数据集。 Map函数负责将输入数据拆分成多个键值对,而Reduce函数则对这些键值对进行汇总和处理,最终输出结果。 通过MapReduce,用户可以轻松实现对海量数据的并行处理和分析。 最后,YARN是Hadoop的资源管理系统,它负责整个集群资源的分配和调度。 YARN的出现极大地提高了Hadoop集群的资源利用率和作业的运行效率。 YARN将资源管理和作业调度分离,使得多个应用程序可以共享同一个Hadoop集群的资源。 这种架构使得Hadoop不再仅仅局限于批处理场景,还能够支持实时计算、交互式查询等多种类型的数据处理任务。 综上所述,HDFS、MapReduce和YARN三者相辅相成,共同构成了Hadoop强大的分布式计算能力。 HDFS提供了海量数据的存储能力,MapReduce赋予了数据处理和分析的能力,而YARN则确保了整个系统的资源得到高效利用。 这三个组件的紧密结合,使得Hadoop能够轻松应对大数据时代带来的挑战,成为企业和研究机构进行大数据处理的首选平台。 例如,在电商领域,Hadoop可以帮助企业分析用户行为数据,挖掘潜在商机;在科研领域,Hadoop可以助力科学家处理复杂的实验数据,加速科研成果的产出。
Hadoop 生态系统组件详解Hadoop 生态系统由多个关键组件构成,它们各自解决特定问题,共同构建了大数据处理的强大平台。 首先,HDFS(Hadoop分布式文件系统)作为基础存储,提供了高容错性和高吞吐量的数据存储,适合处理大型数据集。 接着是MapReduce,它是一个计算模型,通过划分为Map和Reduce步骤,实现分布式并行处理,适合大量数据的计算任务。 HBase 则是一个可扩展的、面向列的数据库,支持实时数据访问,尤其适合与MapReduce结合使用。 Hive是数据仓库工具,提供结构化数据处理,类似SQL的查询语言使数据分析更为便捷。 Pig则提供了一种更抽象的编程模型,用于简化数据处理流程。 在分布式一致性方面,ZooKeeper扮演着重要角色,解决分布式系统中的决策一致性和数据管理问题。 Mahout负责机器学习算法的扩展,Flume负责日志收集,而Sqoop则负责数据在结构化和Hadoop之间的数据交换。 Accumulo是一个分布式、高性能的存储解决方案,Spark则是一个快速的通用计算引擎,优化了迭代任务。 Avro作为数据序列化系统,解决了Hadoop RPC的性能瓶颈问题。 此外,Apache Crunch简化了MapReduce任务编写,Hue提供了Hadoop的用户界面,Impala提供快速查询,而Kafka则支持实时流处理。 Kudu和Oozie分别关注列式存储和工作流调度,Sentry负责实时错误追踪。 每个组件都在Hadoop生态系统中发挥着不可或缺的作用,共同构建了大数据处理的完整解决方案。

Hadoop的核心组件是分布式文件系统(HDFS)和分布式计算框架(MapReduce)。 首先,让我们详细了解一下HDFS(Hadoop Distributed File System)。 HDFS是Hadoop生态系统中的关键组件,主要用于存储大规模数据集。 它的设计目的是确保数据的高可靠性和高可用性。 为了实现这一目标,HDFS将数据分散存储在集群的多个节点上,并支持数据冗余备份。 这种分布式存储方式不仅提高了数据的容错性,还使得Hadoop系统能够高效地处理大规模数据。 接下来是MapReduce,这是Hadoop中的另一个核心组件。 MapReduce是一个编程模型,用于将大规模数据处理作业拆分成小的任务,并在集群中并行执行。 通过将数据分成多个小块,并将计算任务分配到多个节点上,MapReduce能够显著提高数据处理的速度和效率。 此外,MapReduce框架还具有自动管理任务调度、容错和负载均衡等功能,进一步简化了大规模数据处理任务的运行过程。 除了HDFS和MapReduce之外,Hadoop还包含其他一些重要组件,如YARN(Yet Another Resource Negotiator)和Hadoop Common等。 YARN是一个资源管理器,负责调度作业、分配资源和监控任务的执行。 它通过智能地管理集群资源,确保Hadoop系统的高效运行。 Hadoop Common则包含一些通用的工具和库,为Hadoop集群提供基本的功能,如配置管理、日志记录和工具类库等。 综上所述,Hadoop的核心组件是分布式文件系统HDFS和分布式计算框架MapReduce。 它们共同构成了Hadoop生态系统的基础,使得用户可以在不了解分布式底层细节的情况下,开发分布式程序,充分利用集群的威力进行高速运算和存储。 通过将这些组件结合起来,Hadoop为用户提供了一个强大而灵活的平台,用于处理和分析大规模数据。
Hadoop是一个开源的分布式处理框架,它能够处理和存储大规模数据集,是大数据处理的重要工具。 Hadoop主要由两个核心组件构成:Hadoop Distributed File System (HDFS) 和 Hadoop MapReduce。 1. Hadoop Distributed File System (HDFS):HDFS是Hadoop的分布式文件系统,设计用来存储和处理大规模的数据集。 它运行在集群的普通硬件上,具有很高的容错性,通过数据复制和分布式处理来保证数据的高可用性。 HDFS将数据分割成块并分布在集群的多个节点上,这样可以在多个节点上并行处理数据,提高数据处理速度。 例如,一个大型企业每天可能产生TB级别的日志数据,这些数据可以存储在HDFS上,并通过Hadoop进行高效处理。 2. Hadoop MapReduce:MapReduce是Hadoop的编程模型,用于大规模数据的并行处理。 它包含两个阶段:Map阶段和Reduce阶段。 在Map阶段,输入数据被分割成小块并由Map任务并行处理;在Reduce阶段,Map任务的输出被汇总并由Reduce任务处理,生成最终结果。 MapReduce能够自动处理并行化和故障恢复,使得开发者能够更容易地编写分布式应用。 例如,通过MapReduce可以编写一个程序来计算网页的访问频率。 Map任务处理每个网页的访问日志,输出网页和访问次数;Reduce任务汇总每个网页的访问次数,得到最终结果。 除了这两个核心组件外,Hadoop生态系统还包括很多其他组件和工具,如HBase(一个分布式的、可伸缩的大数据存储库)、Hive(用于数据查询和分析的数据仓库工具)、Pig(用于分析大数据的高级脚本语言)等,这些组件和工具使得Hadoop成为一个功能强大的大数据处理平台。
Hadoop是一种专门设计用于大规模分布式计算和存储的框架,其核心组件是HDFS(Hadoop Distributed File System)和MapReduce。 在Hadoop的工作流程中,HDFS扮演着关键角色。 它由一个主节点(Namenode,早期版本仅有一个,而在2.x版本中可有多个)和多个从节点(Datanode)组成。 Namenode主要负责接收用户操作请求,这些请求可能来源于开发工程师编写的Java代码或命令行客户端。 它负责维护文件系统的目录结构,确保数据的逻辑关系和位置信息得到准确管理,并管理文件与数据块(每个64M)之间的关联。 在Hadoop的存储策略中,文件被分割成多个数据块,彼此之间具有顺序关系。 Namenode负责跟踪每个数据块的分布情况,以及它们归属于哪个Datanode。 这种设计使得Hadoop能够高效地存储和管理海量数据,实现大规模数据的分布式处理。
内容声明:
1、本站收录的内容来源于大数据收集,版权归原网站所有!
2、本站收录的内容若侵害到您的利益,请联系我们进行删除处理!
3、本站不接受违法信息,如您发现违法内容,请联系我们进行举报处理!
4、本文地址:http://www.jujiwang.com/article/cb457ef8589979dfaecd.html,复制请保留版权链接!

欢迎来到电影剪辑的精彩世界!如果您渴望将您的视频愿景变成现实,Movieclip就是您的终极解决方案,在全面的指南中,我们将逐步引导您了解Movieclip的强大功能,让您掌控您的剪辑过程,创造出令人惊叹的杰作,Movieclip的优势用户友好的界面,即使是初学者也可以轻松上手,强大的编辑工具,让您剪切、修剪、合并和添加效果,广泛的媒...。
技术教程 2024-09-24 08:04:49
引言VBscript,VisualBasicScriptingEdition,是一种微软开发的脚本语言,广泛应用于网页制作、系统自动化和后端开发,由于其简单易学、功能强大,VBscript深受广大开发者的喜爱,本教程旨在全面解析VBscript的基础语法,为初学者和有经验的程序员提供一个全面的参考,数据类型VBscript支持多种数据...。
技术教程 2024-09-16 05:45:34
引言随着技术的不断进步,网页设计趋势也在不断演变,为了确保您的网站在竞争中脱颖而出并提供最佳的用户体验,了解最新的趋势至关重要,本文将深入探讨当前网页模版中普遍存在的设计和功能趋势,帮助您的网站跟上时代步伐,现代设计原则简约主义,注重干净的线条、负空间和简单的配色方案,响应式设计,确保网站在所有设备,台式机、笔记本电脑、移动设备,上都...。
最新资讯 2024-09-16 00:50:30

表单是一种收集用户输入的数据结构,为了确保表单对所有用户,包括残疾用户,都可访问,重要的是使用语义化的HTML标签,使用喇叭的最佳时间使用喇叭的最佳时间是什么时候,提交语义化HTML标签以下是一些可用来创建可访问表单的语义化HTML标签,<,label>,将标签与表单控件关联,为屏幕阅读器提供信息,<,input>,...。
本站公告 2024-09-15 22:30:52

并发编程的三要素并发编程是编写可同时执行多个任务的程序的过程,为了实现并发性,程序必须满足以下三个要素,并发性,程序能够同时执行多个任务,而这些任务可以独立运行或并行运行,共享状态,并发任务可以访问和修改同一共享状态,例如内存中的变量或数据结构,同步,并发任务必须以协调一致的方式访问共享状态,以避免数据竞争,racecondition...。
本站公告 2024-09-15 20:40:38

使用嵌套过多,因为这会降低性能,使用命名范围来增强可读性和可维护性,使用错误处理函数来处理错误值,通过使用快捷键和功能区自定义来提高工作效率,结论学习Excel公式是一个持续的过程,需要练习和探索,通过掌握本指南中的基础知识和高级技术,你可以解锁Excel的真正力量并提高你的数据分析和工作表管理技能,...。
互联网资讯 2024-09-13 14:06:14

励,使用商店,你可以使用游戏中的货币,钻石,在商店购买使者进阶图纸,使用year函数,你可以检查游戏中使者进阶图纸的可用性,例如,以下代码将返回当前年份中所有可用使者进阶图纸的列表,SELECTFROMtable,nameWHEREyear,date,available,=year,CURRENT,DATE,总结year函数是一个多...。
本站公告 2024-09-13 12:02:48
爬虫程序,又称网络爬虫,是一种自动化程序,用于从互联网上收集数据,它们可以执行从简单页面抓取到复杂数据分析的各种任务,尽管爬虫程序非常有用,但重要的是要意识到使用它们的道德和责任,爬虫程序的道具有哪些,爬虫程序可以拥有各种功能,包括,从网站上抓取HTML、CSS和JavaScript文件分析页面内容,提取文本、图像和链接遵守网站的ro...。
互联网资讯 2024-09-12 23:13:05

简介在处理数据时,四舍五入是一个重要的操作,可以提高数据精度和可用性,在Excel中,Roundup函数是一个功能强大的工具,可以轻松地四舍五入数字,本文将深入探讨Roundup函数,包括其语法、用法、示例和高级技巧,语法=ROUNDUP,number,num,digits,number,要四舍五入的数字,num,digits,以小数...。
最新资讯 2024-09-12 17:56:24

超越想象的H5游戏开发,H5游戏平台源码的终极秘诀引言在当今快节奏的数字世界中,H5游戏已成为吸引受众和提供沉浸式娱乐体验的强大工具,随着H5游戏平台源码的不断发展,开发者现在有能力创造以前无法想象的游戏体验,本文将深入探讨H5游戏平台源码的奥秘,揭示其创建令人惊叹的H5游戏的终极秘诀,H5游戏平台源码的概念H5游戏平台源码是一种软件...。
技术教程 2024-09-11 09:49:46
在本文中,我们将介绍如何使用JavaXFire框架创建、部署和消费Web服务,XFire是Apache捐赠给Apache软件基金会的开源Web服务框架,XFire提供了一个易于使用的API来创建和部署Web服务,并通过支持多种传输协议,包括HTTP、SOAP和REST,和数据绑定框架,包括JAXB和XStream,来支持广泛的Web服...。
最新资讯 2024-09-10 23:55:55
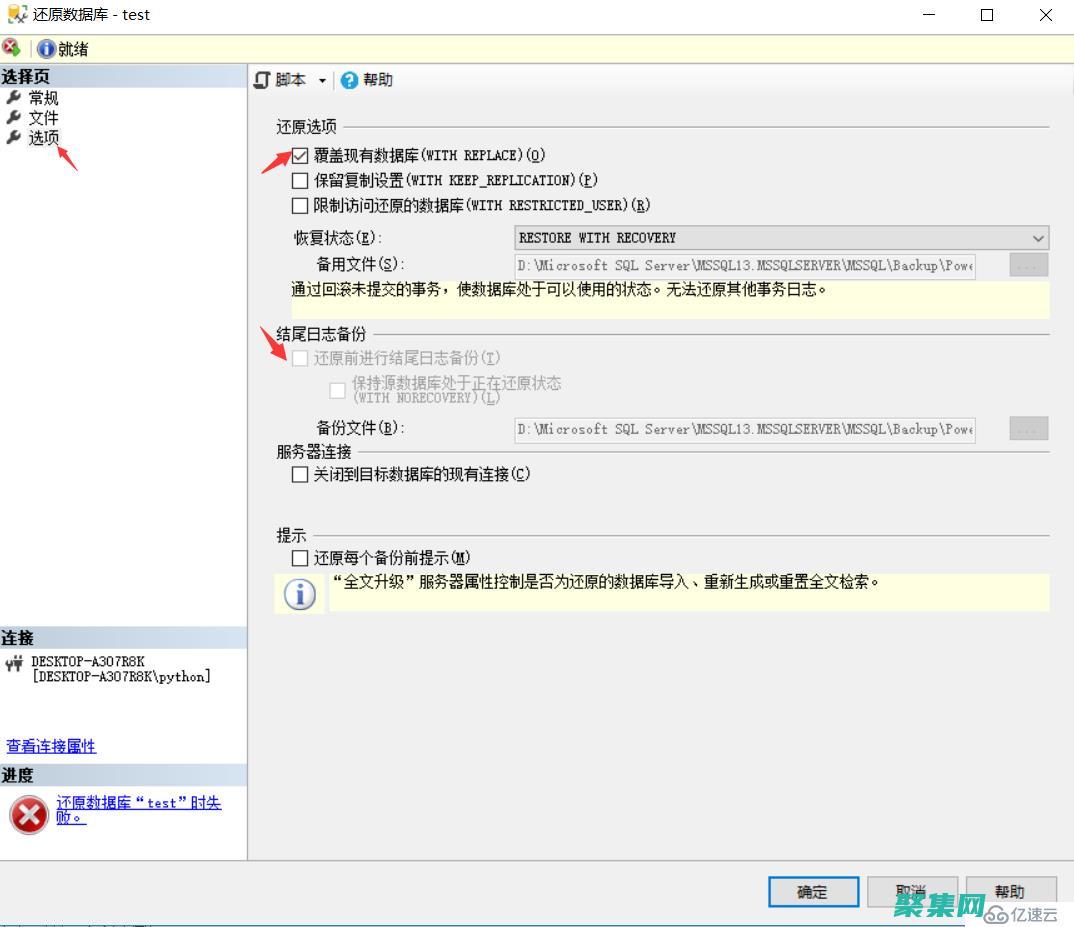
数据库是企业和组织的关键资产,其包含着重要的业务数据,为了维护数据安全性和确保业务连续性,定期备份和恢复数据库至关重要,备份的重要性备份是创建和存储数据库副本的过程,以下是备份的几个重要性,数据保护,备份提供了一种在数据丢失或损坏,例如由于硬件故障、软件故障或人为错误,时恢复数据的机制,业务连续性,在发生灾难或停机时,备份允许企业快速...。
本站公告 2024-09-10 19:45:11