(换肤)
语言:

文章编号:10588时间:2024-09-28人气:

你是音乐爱好者吗?是否厌倦了流媒体音乐服务中有限的音乐选择?如果是这样,那么使用 QQ 音乐爬虫创建自己的音乐库可能正是您需要做的。
QQ 音乐爬虫是一种软件程序,用于从 QQ 音乐网站提取音乐文件。它本质上是一个自动化程序,可以为您执行手动下载音乐文件的繁琐任务。


使用 QQ 音乐爬虫创建自己的音乐库是一种创建和享受您喜爱的音乐便捷方式。它可以让您建立一个不断增长的音乐收藏,并随时随地离线收听。在使用爬虫时要考虑版权问题和潜在的限制,并确保您使用的是信誉良好的程序。
近年来,随着互联网技术的不断发展,越来越多的人开始使用爬虫来获取音乐。 通过爬虫获取音乐,不仅可以免费获取大量的音乐资源,还可以快速地找到自己喜欢的音乐。 下面我们来介绍一下如何用爬虫获取音乐。 首先,我们需要选择一个合适的网站。 目前市面上有很多音乐网站,如酷狗音乐、网易云音乐、QQ音乐等。 我们可以根据自己的喜好选择一个合适的网站。 接着,我们需要了解一些基本的爬虫知识。 爬虫是一种自动化获取网页信息的工具,可以模拟人类操作,自动抓取网页上的信息,并进行处理和分析。 在使用爬虫时,我们需要了解网页的结构和编码方式。 然后,我们需要选择一个合适的编程语言。 目前常用的编程语言有Python、Java、JavaScript等。 其中,Python是最为流行的语言之一,因为它简单易学、功能强大、支持多种操作系统,并且有丰富的第三方库和工具。 最后,我们需要编写爬虫程序。 在编写爬虫程序时,我们需要根据网页的结构和编码方式,使用相应的爬虫框架和库。 例如,使用Python中的requests库和BeautifulSoup库可以轻松地获取网页信息,并提取出我们需要的音乐链接。 需要注意的是,在使用爬虫获取音乐时,我们需要遵守相关法律法规,不得侵犯他人的版权和隐私。 另外,我们还需要注意数据的安全和保护,避免泄露个人信息和数据。 综上所述,使用爬虫获取音乐可以帮助我们快速地获取大量的音乐资源,但是也需要我们遵守相关法律法规和保护数据安全。
不同机构课程安排不同,每个人需求不一样,选择上也是存在差异,建议根据自身需求,实地体验一下。 课程安排:阶段一:Python开发基础Python全栈开发与人工智能之Python开发基础知识学习内容包括:Python基础语法、数据类型、字符编码、文件操作、函数、装饰器、迭代器、内置方法、常用模块等。 阶段二:Python高级编程和数据库开发Python全栈开发与人工智能之Python高级编程和数据库开发知识学习内容包括:面向对象开发、Socket网络编程、线程、进程、队列、IO多路模型、Mysql数据库开发等。 阶段三:前端开发Python全栈开发与人工智能之前端开发知识学习内容包括:Html、CSS、JavaScript开发、Jquery&bootstrap开发、前端框架VUE开发等。 阶段四:WEB框架开发Python全栈开发与人工智能之WEB框架开发学习内容包括:Django框架基础、Django框架进阶、BBS+Blog实战项目开发、缓存和队列中间件、Flask框架学习、Tornado框架学习、Restful API等。 阶段五:爬虫开发Python全栈开发与人工智能之爬虫开发学习内容包括:爬虫开发实战。 阶段六:全栈项目实战Python全栈开发与人工智能之全栈项目实战学习内容包括:企业应用工具学习、CRM客户关系管理系统开发、路飞学城在线教育平台开发等。 阶段七:数据分析Python全栈开发与人工智能之数据分析学习内容包括:金融量化分析。 阶段八:人工智能Python全栈开发与人工智能之人工智能学习内容包括:机器学习、图形识别、无人机开发、无人驾驶等。 阶段九:自动化运维&开发Python全栈开发与人工智能之自动化运维&开发学习内容包括:CMDB资产管理系统开发、IT审计+主机管理系统开发、分布式主机监控系统开发等。 阶段十:高并发语言GO开发Python全栈开发与人工智能之高并发语言GO开发学习内容包括:GO语言基础、数据类型与文件IO操作、函数和面向对象、并发编程等。
本篇文章给大家分享的内容是如何利用Python爬取网易云音乐热门评论,有着一定的参考价值,有需要的朋友可以参考一下前言最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧。 获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据。 但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取数据。 那么这个时候该怎么办呢?有一种比较好的办法是通过网络爬虫,即编写计算机程序伪装成用户去获得想要的数据。 利用计算机的高效,我们可以轻松快速地获取数据。 关于爬虫那么该如何写一个爬虫呢?有很多种语言都可以写爬虫,比如Java,php,python 等,我个人比较喜欢使用python。 因为python不仅有着内置的功能强大的网络库,还有诸多优秀的第三方库,别人直接造好了轮子,我们直接拿过来用就可以了,这为写爬虫带来了极大的方便。 不夸张地说,使用不到10行python代码其实就可以写一个小小的爬虫,而使用其他的语言可以要多写很多代码,简洁易懂正是python的巨大的优势。 好了废话不多说,进入今天的正题。 最近几年网易云音乐火了起来,我自己就是网易云音乐的用户,用了几年了。 以前用的是QQ音乐和酷狗,通过我自己的亲身经历来看,我觉得网易云音乐最优特色的就是其精准的歌曲推荐和独具特色的用户评论(郑重声明!!!这不是软文,非广告!!!仅代表个人观点,非喜勿喷!)。 经常一首歌曲下面会有一些被点赞众多的神评论。 加上前些日子网易云音乐将精选用户评论搬上了地铁,网易云音乐的评论又火了一把。 所以我想对网易云的评论进行分析,发现其中的规律,特别是分析一些热评具有什么共同的特点。 带着这个目的,我开始了对网易云评论的抓取工作。 网络库Python内置了两个网络库urllib和urllib2,但是这两个库使用起来不是特别方便,所以在这里我们使用一个广受好评的第三方库requests。 使用requests只用很少的几行代码就可以实现设置代理,模拟登陆等比较复杂的爬虫工作。 如果已经安装pip的话,直接使用pip install requests 即可安装。 中文文档地址在此大家有什么问题可以自行参考官方文档,上面会有非常详细的介绍。 至于urllib和urllib2这两个库也是比较有用的,以后如果有机会我会再给大家介绍一下。 工作原理在正式开始介绍爬虫之前,首先来说一下爬虫的基本工作原理,我们知道我们打开浏览器访问某个网址本质上是向服务器发送了一定的请求,服务器在收到我们的请求之后,会根据我们的请求返回数据,然后通过浏览器将这些数据解析好,呈现在我们的面前。 如果我们使用代码的话,就要跳过浏览器的这个步骤,直接向服务器发送一定的数据,然后再取回服务器返回的数据,提取出我们想要的信息。 但是问题是,有的时候服务器需要对我们发送的请求进行校验,如果它认为我们的请求是非法的,就会不返回数据,或者返回错误的数据。 所以为了避免发生这种情况,我们有的时候需要把程序伪装成一个正常的用户,以便顺利得到服务器的回应。 如何伪装呢?这就要看用户通过浏览器访问一个网页与我们通过程序访问一个网页之间的区别。 通常来说,我们通过浏览器访问一个网页,除了发送访问的url之外,还会给服务发送额外的信息,比如headers(头部信息)等,这就相当于是请求的身份证明,服务器看到了这些数据,就会知道我们是通过正常的浏览器访问的,就会乖乖地返回数据给我们了。 模拟登陆所以我们程序就得像浏览器一样,在发送请求的时候,带上这些标志着我们身份的信息,这样就能顺利拿到数据。 有的时候,我们必须在登录状态下才能得到一些数据,所以我们必须要模拟登录。 本质上来说,通过浏览器登录就是post一些表单信息给服务器(包括用户名,密码等信息),服务器校验之后我们就可以顺利登录了,利用程序也是一样,浏览器post什么数据,我们原样发送就可以了。 关于模拟登录,我后面会专门介绍一下。 当然事情有的时候也不会这么顺利,因为有些网站设置了反爬措施,比如如果访问过快,有时候会被封ip(典型的比如豆瓣)。 这个时候我们还得要设置代理服务器,即变更我们的ip地址,如果一个ip被封了,就换另外一个ip,具体怎么做,这些话题以后慢慢再说。 小技巧 最后,再介绍一个我认为在写爬虫过程中非常有用的一个小技巧。 如果你在使用火狐浏览器或者chrome的话,也许你会注意到有一个叫作开发者工具(chrome)或者web控制台(firefox)的地方。 这个工具非常有用,因为利用它,我们可以清楚地看到在访问一个网站的过程中,浏览器到底发送了什么信息,服务器究竟返回了什么信息,这些信息是我们写爬虫的关键所在。 下面你就会看到它的巨大用处。 如何爬取评论首先打开网易云音乐的网页版,随便选择一首歌曲打开它的网页,这里我以周杰伦的《晴天》为例。 如下图:接下来打开web控制台(chrome的话打开开发者工具,如果是其他浏览器应该也是类似),如下图:然后这个时候我们需要点选网络,清除所有的信息,然后点击重新发送(相当于是刷新浏览器),这样我们就可以直观看到浏览器发送了什么信息以及服务器回应了什么信息。 如下图:刷新之后得到的数据如下可以看到浏览器发送了非常多的信息,那么哪一个才是我们想要的呢?这里我们可以通过状态码做一个初步的判断,status code(状态码)标志了服务器请求的状态,这里状态码为200即表示请求正常,而304则表示不正常(状态码种类非常多,如果要想详细了解可以自行搜索,这里不说304具体的含义了)。 所以我们一般只用看状态码为200的请求就可以了,还有就是,我们可以通过右边栏的预览来粗略观察服务器返回了什么信息(或者查看响应)。 如下图:通过这两种方法结合一般我们就可以快速找到我们想要分析的请求。 注意图5中的请求网址一栏即是我们想要请求的网址,请求的方法有两种:get和post,还有一个需要重点关注的就是请求头,里面包含了user-Agent(客户端信息),refrence(从何处跳转过来)等多种信息,一般无论是get还是post方法我们都会把头部信息带上。 头部信息如下图:另外还需要注意的是:get请求一般就直接把请求的参数以 ?parameter1=value1¶meter2=value2 等这样的形式发送了,所以不需要带上额外的请求参数,而post请求则一般需要带上额外的参数,而不直接把参数放在url当中,所以有的时候我们还需要关注参数这一栏。 经过仔细寻找,我们终于找到原来与评论相关的请求在这个请求当中,如下图:点开这个请求,我们发现它是一个post请求,请求的参数有两个,一个是params,还有一个是encSecKey,这两个参数的值非常的长,感觉应该像是加密过的。 如下图:服务器返回的和评论相关的数据为json格式的,里面含有非常丰富的信息(比如有关评论者的信息,评论日期,点赞数,评论内容等等),如下图9所示:(其实hotComments为热门评论,comments为评论数组)至此,我们已经确定了方向了,即只需要确定params和encSecKey这两个参数值即可,这个问题困扰了我一下午,我弄了很久也没有搞清楚这两个参数的加密方式,但是我发现了一个规律,中 R_SO_4_ 后面的数字就是这首歌的id值,而对于不同的歌曲的param和encSecKey值,如果把一首歌比如A的这两个参数值传给B这首歌,那么对于相同的页数,这种参数是通用的,即A的第一页的两个参数值传给其他任何一首歌的两个参数,都可以获得相应歌曲的第一页的评论,对于第二页,第三页等也是类似。 但是遗憾的是,不同的页数参数是不同的,这种办法只能抓取有限的几页(当然抓取评论总数和热门评论已经足够了),如果要想抓取全部数据,就必须搞明白这两个参数值的加密方式。 以为没有搞明白,昨天晚上我带着这个问题去知乎搜索了一下,居然真的被我找到了答案。 @平胸小仙女 这位知友详细说明了如何破解这两个参数的加密过程,我研究了一下,发现还是有点小复杂的,按照知友写的方法,我改动了一下,就成功得到了全部的评论。 这里要对知乎@平胸小仙女 表示感谢。 到此为止,如何抓取网易云音乐的评论全部数据就全部讲完了。 按照惯例,最后上代码,亲测有效:#!/usr/bin/env python2.7 # -*- coding: utf-8 -*- # @Time : 2017/3/28 8:46 # @Author : Lyrichu # @Email : # @File : NetCloud_ @Description: 网易云音乐评论爬虫,可以完整爬取整个评论 部分参考了@平胸小仙女的文章来源:知乎 from import AES import base64 import requests import json import codecs import time # 头部信息 headers = { , Accept-Language:zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3, Accept-Encoding:gzip, deflate, Content-Type:application/x-www-form-urlencoded, Cookie:_ntes_nnid=b04b121e078dee797cdb30e0fd,27; _ntes_nuid=b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A80; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.e63af8; vjlast=..21; __gads=ID=a9eed5e3cae4d252:T=:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.69.05.42; P_INFO=||1|Study|00&99|null&null&null#hub #0#0|&1|study_client|; NTES_CMT_USER_INFO=%7Cm155****4439%7Chttps%3A%2F%%2Fe%%2Ftie%2Fimages%2Fyun%2Fphoto_default_%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2..; __utma=.....8; __utmc=; __utmz==baidu|utmccn=(organic)|utmcmd=organic; playerid=; __utmb=.23.10., Connection:keep-alive, Referer:}# 设置代理服务器 proxies= { http::https::}# offset的取值为:(评论页数-1)*20,total第一页为true,其余页为false # First_param = {rid:, offset:0, total:true, limit:20, csrf_token:} # 第一个参数 second_param = # 第二个参数 # 第三个参数 third_param = 00e0b509f6259df8642dbcdfec152b5ff68ace615bb7bb3ab17a876aea8a5aa76d2eec4ee341ffccfe0312ecbdacaf6c9d05c4f7f0c3685b7a46beecce10b424d813cfe4875d3eb97ddefd546b8e289dc6935b3ece0462db0a22b8e7 # 第四个参数 forth_param = 0CoJUm6Qyw8W8jud # 获取参数 def get_params(page): # page为传入页数 iv = first_key = forth_param second_key = 16 * F if(page == 1): # 如果为第一页 first_param = {rid:, offset:0, total:true, limit:20, csrf_token:} h_encText = AES_encrypt(first_param, first_key, iv) else: offset = str((page-1)*20) first_param = {rid:, offset:%s, total:%s, limit:20, csrf_token:} %(offset,false) h_encText = AES_encrypt(first_param, first_key, iv) h_encText = AES_encrypt(h_encText, second_key, iv) return h_encText # 获取 encSecKey def get_encSecKey(): encSecKey = aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2ed94a02ca919de7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3fed39e7de08fce26dbc4484a01c76f739ec return encSecKey # 解密过程 def AES_encrypt(text, key, iv): pad = 16 - len(text) % 16 text = text + pad * chr(pad) encryptor = (key, _CBC, iv) encrypt_text = (text) encrypt_text = base64.b64encode(encrypt_text) return encrypt_text # 获得评论json数据 def get_json(url, params, encSecKey): data = { params: params, encSecKey: encSecKey } response = (url, headers=headers, data=data,proxies = proxies) return # 抓取热门评论,返回热评列表 def get_hot_comments(url): hot_comments_list = [] hot_comments_(u用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容) params = get_params(1) # 第一页 encSecKey = get_encSecKey() json_text = get_json(url,params,encSecKey) json_dict = (json_text) hot_comments = json_dict[hotComments] # 热门评论 print(共有%d条热门评论! % len(hot_comments)) for item in hot_comments: comment = item[content] # 评论内容 likedCount = item[likedCount] # 点赞总数 comment_time = item[time] # 评论时间(时间戳) userID = item[user][userID] # 评论者id nickname = item[user][nickname] # 昵称 avatarUrl = item[user][avatarUrl] # 头像地址 comment_info = userID + + nickname + + avatarUrl + + comment_time + + likedCount + + comment + u hot_comments_(comment_info) return hot_comments_list # 抓取某一首歌的全部评论 def get_all_comments(url): all_comments_list = [] # 存放所有评论 all_comments_(u用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容) # 头部信息 params = get_params(1) encSecKey = get_encSecKey() json_text = get_json(url,params,encSecKey) json_dict = (json_text) comments_num = int(json_dict[total]) if(comments_num % 20 == 0):
内容声明:
1、本站收录的内容来源于大数据收集,版权归原网站所有!
2、本站收录的内容若侵害到您的利益,请联系我们进行删除处理!
3、本站不接受违法信息,如您发现违法内容,请联系我们进行举报处理!
4、本文地址:http://www.jujiwang.com/article/06019f09d7a6740f0a35.html,复制请保留版权链接!

概述AndroidSDK,软件开发工具包,是一个必不可少的工具包,为Android应用程序开发提供了全面的工具和资源,无论您是经验丰富的开发者还是刚开始踏上移动开发之旅,下载和安装AndroidSDK都是制定成功应用程序的至关重要的一步,本文将指导您完成下载和安装AndroidSDK的过程,为您的移动开发之旅奠定坚实的基础,步骤1,下...。
技术教程 2024-09-27 19:10:18
在现代Web开发中,数据网格,DataGrid,已成为必不可少的组件,用于可视化和操纵数据,它们提供了用户友好的界面,使开发人员能够轻松地将数据呈现得清晰明了,为了实现功能齐全的应用程序,至关重要的是将DataGrid与后端系统集成,以提供对数据的无缝访问,DataGrid的作用DataGrid是表格视图组件,用于显示、筛选、排序和编...。
技术教程 2024-09-26 20:39:53

NumPy和SciPy是Python中用于数值计算的两个强大的库,NumPy提供了一个多维数组对象,以及各种数学运算函数,SciPy提供了更多高级的科学和工程工具,例如优化、积分和线性代数,numpy.arrange函数numpy.arrange,函数用于创建一组等间隔的数字,它类似于Python的range,函数,但它返回一个N...。
本站公告 2024-09-24 22:03:05
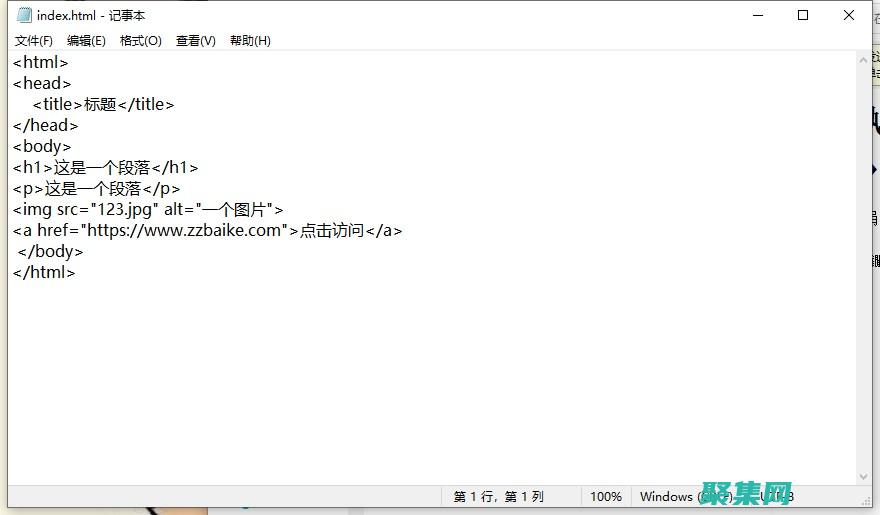
什么是HTML编码,HTML编码是一种将特殊字符转换为HTML实体的方法,HTML实体是使用和符号表示的特殊字符,例如,&,表示&,字符,为什么需要HTML编码,HTML编码对于在Web页面上正确显示某些字符非常重要,例如,如果未对&,字符进行编码,则它会被解释为HTML实体,并且不会显示为实际的&,字符,如何...。
互联网资讯 2024-09-24 20:00:18
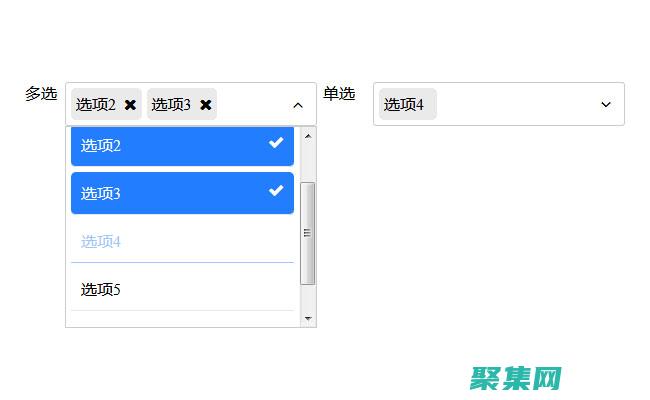
下拉框是一个常见的用户界面元素,它允许用户从一组选项中选择一个值,下拉框可以是可访问的,这意味着所有用户都可以轻松使用,包括残障人士,确保所有用户都能轻松使用下拉框的最佳实践使用明确的标签,下拉框的标签应该准确描述下拉框的目的,例如,一个下拉框用于选择国家,地区,它的标签应该是选择国家,地区,提供键盘导航,用户应该能够使用键盘访问和导...。
互联网资讯 2024-09-24 06:42:29

前言在C语言编程中,`fscanf`函数是一个用于从文件中读取格式化数据的强大工具,它提供了灵活且高效的方式来解析各种类型的文件格式,使其成为处理文件I,O时不可或缺的函数,为了充分理解和利用`fscanf`的能力,本文将深入剖析其工作原理,揭示其读取文件数据背后的机制,剖析fscanf`fscanf`函数的原型如下,cintfsca...。
最新资讯 2024-09-23 17:13:09

文档和图像管理是管理和组织文档和图像文件的过程,它包括将文件存储在中央位置、对文件进行分类和组织以及管理对文件的访问权限,图像文档的定义图像文档是指包含图像数据的文档文件,图像文档可以是各种格式,包括,JPEGPNGGIFTIFFPDF文档和图像管理的重要性文档和图像管理对于组织高效运行至关重要,有效的文档和图像管理可以帮助组织,提高...。
本站公告 2024-09-16 08:15:32
概览本教程将指导您使用Informix中的动态SQL和存储过程来提高您的函数编程技能,这些技术将使您能够创建动态、可重用和高效的函数,动态SQL动态SQL允许您在运行时构造SQL语句并执行它们,这为您提供了创建通用函数的灵活性,这些函数可以接受可变参数并针对不同的数据动态生成SQL,创建动态SQL函数要使用动态SQL,您需要创建具有D...。
本站公告 2024-09-08 09:43:57

在实时通信应用中,数据交互是至关重要的,小程序云开发数据库,凭借其稳定的性能、低延迟和高并发特性,为实时通信应用提供了强大的数据交互保障,极大提升了用户体验,云开发数据库的功能优势实时更新,数据变动实时推送到客户端,确保数据实时性和一致性,低延迟,采用高性能云服务器,确保网络请求响应速度极快,实现即时数据交互,高并发,支持海量并发请求...。
本站公告 2024-09-07 21:10:46
在Windows编程领域,VCL,VisualComponentLibrary,是一组强大的控件,可用于创建具有高性能和美观的应用程序,如果您使用Delphi或C,Builder等基于VCL的IDE,那么了解这些控件的用途和最佳实践将至关重要,VCL控件概述VCL控件是预先构建的可视化组件,它提供了一系列功能,例如按钮、文本框、列表...。
技术教程 2024-09-07 18:08:31

引言JavaFX是Java平台上的一个图形用户界面,GUI,工具包,它允许开发人员使用Java轻松创建丰富的GUI应用程序,凭借其卓越的性能、跨平台兼容性和易用性,JavaFX已成为创建现代、引人入胜的应用程序的首选,Java9对JavaFX进行了多项改进,增强了开发人员构建更具响应性、美观和高效的GUI应用程序的能力,本文将深入探讨...。
本站公告 2024-09-07 09:39:12
您正在寻找可让您轻松创建自定义且可扩展的在线论坛的ASP源代码吗,我们为您提供帮助!本文将为您提供一个ASP论坛源码,您可以使用它来构建一个强大的在线论坛,并根据您的特定需求进行定制,ASP论坛源码特性可定制的布局和主题,使用HTML和CSS轻松定制您的论坛外观和布局,用户注册和登录,允许用户创建帐户并登录到论坛,论坛类别和主题,组织...。
技术教程 2024-09-05 17:49:16